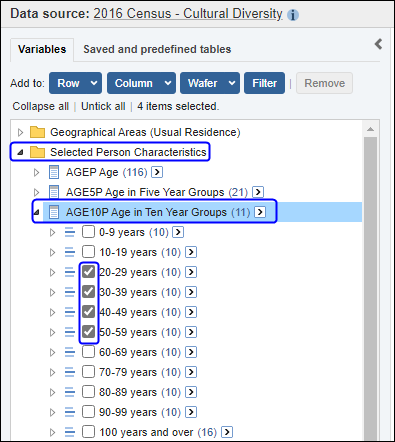
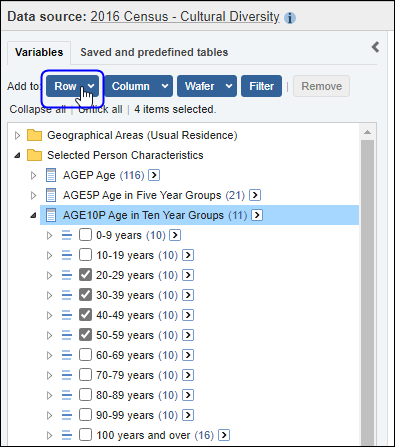
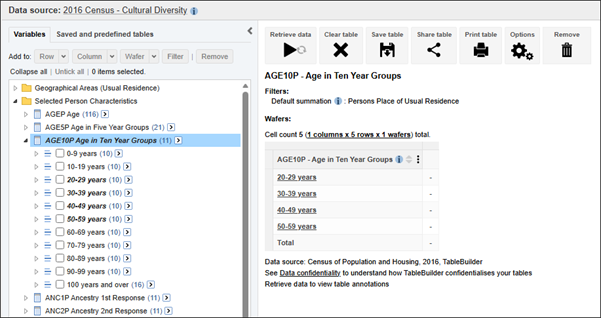
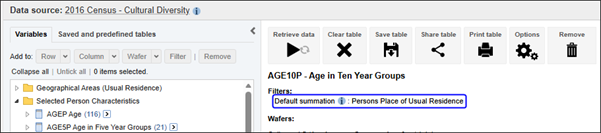
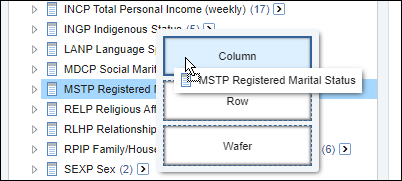
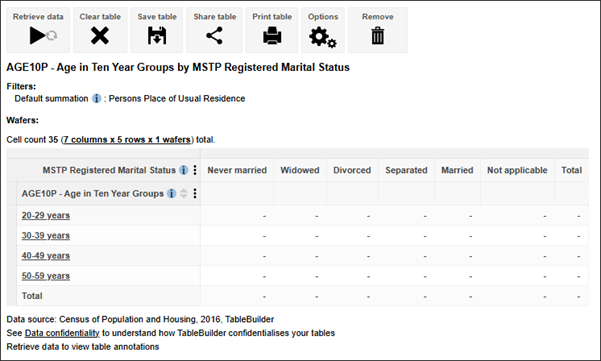
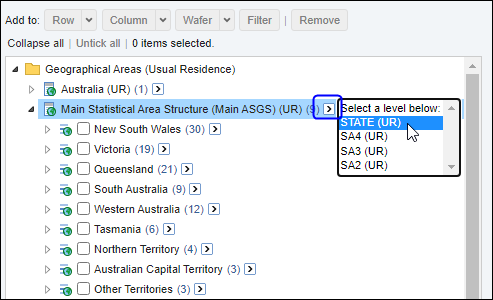
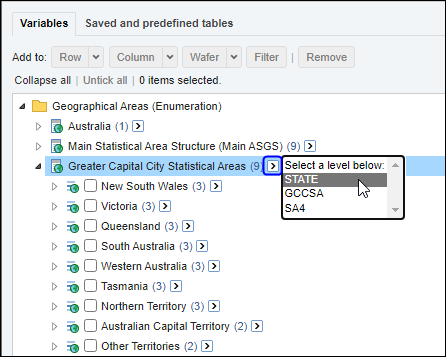
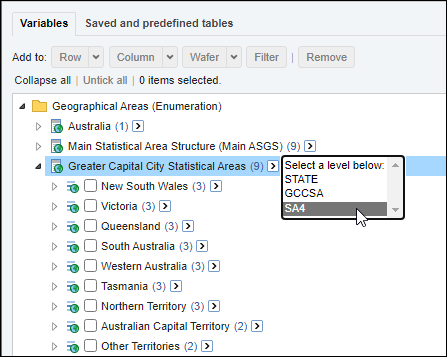
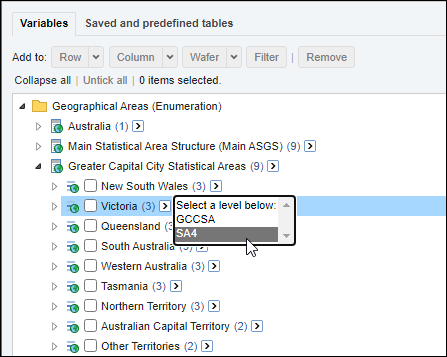
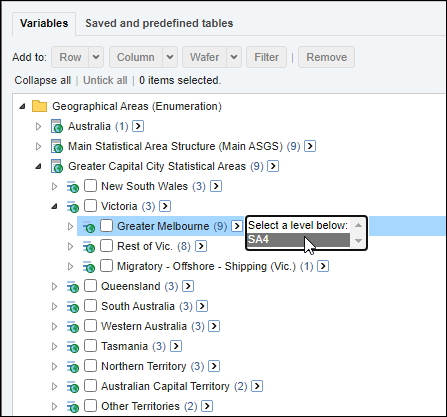
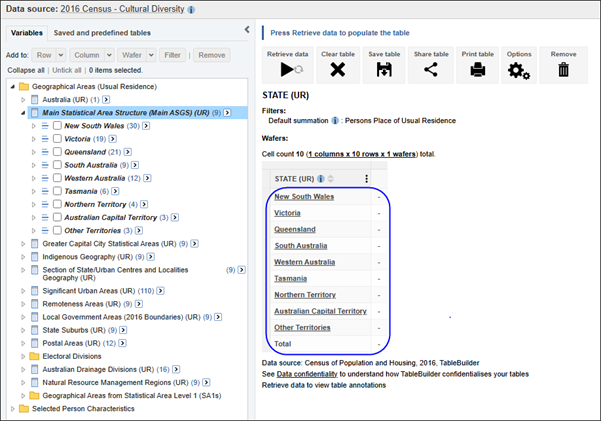
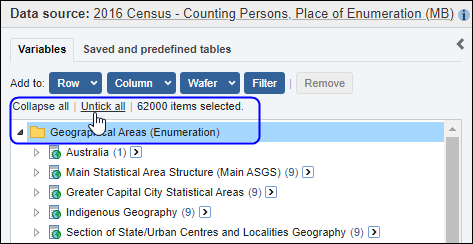
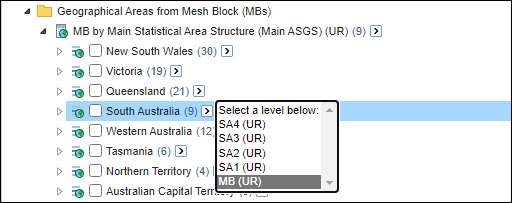
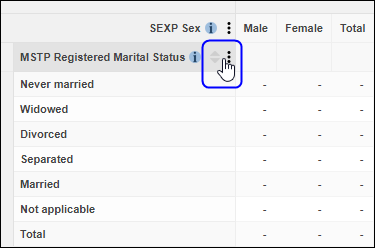
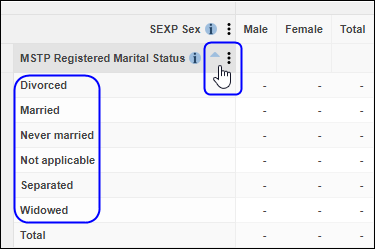
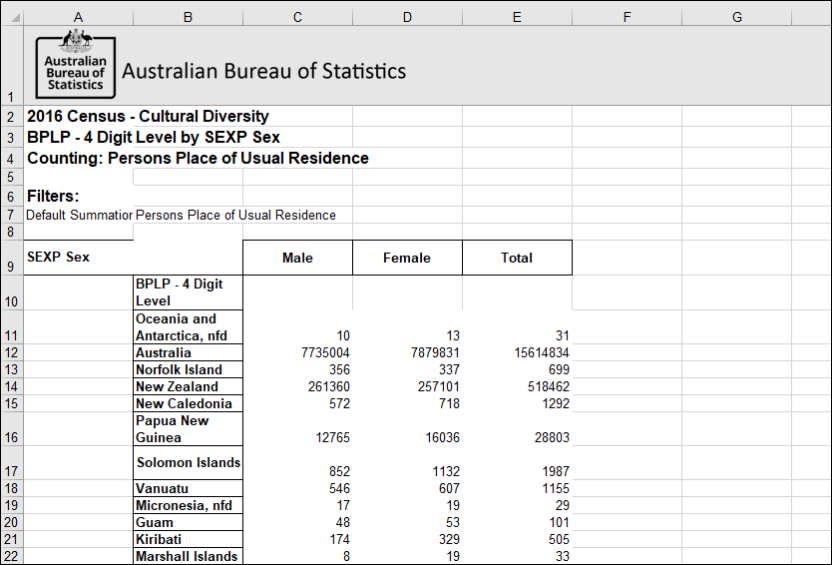
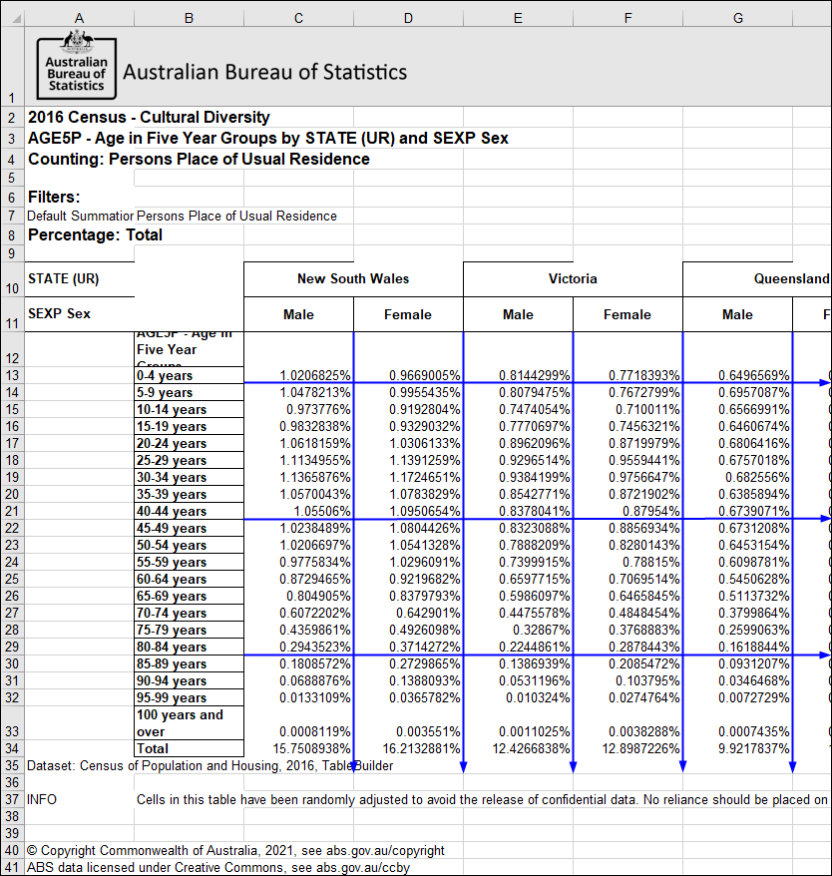
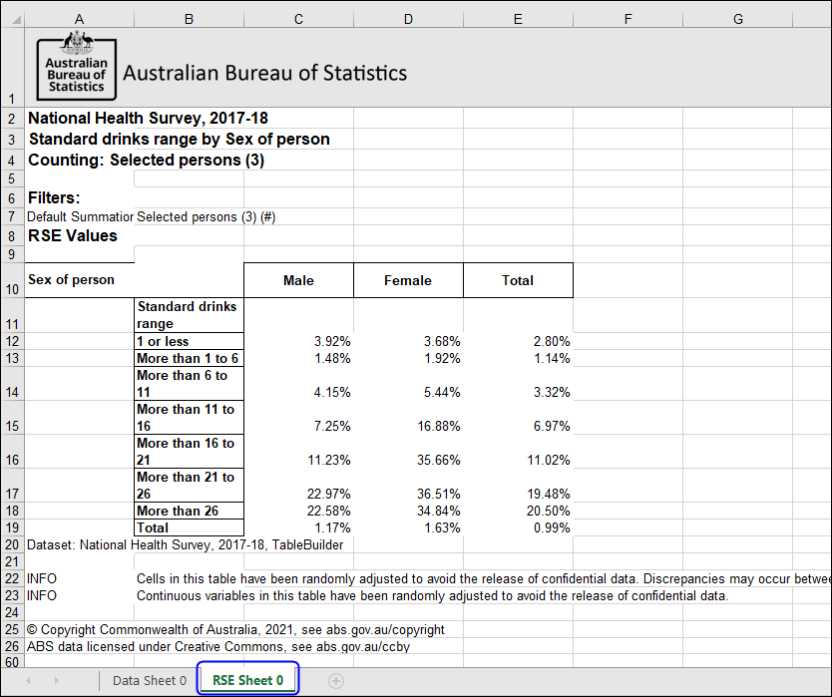
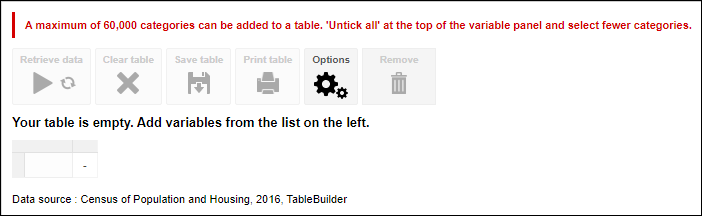
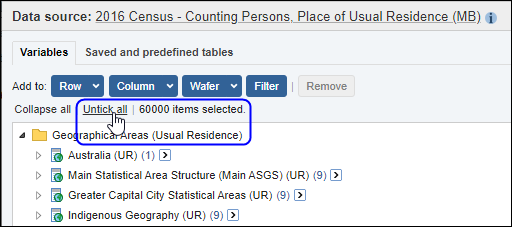
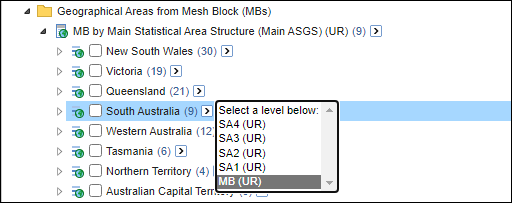
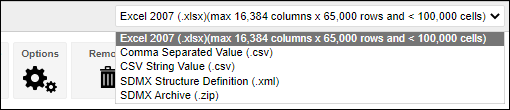
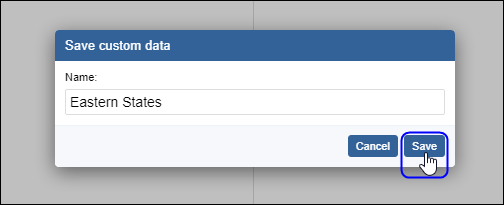
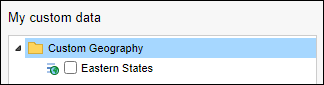
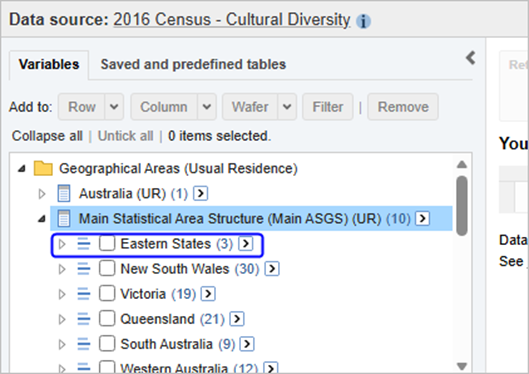
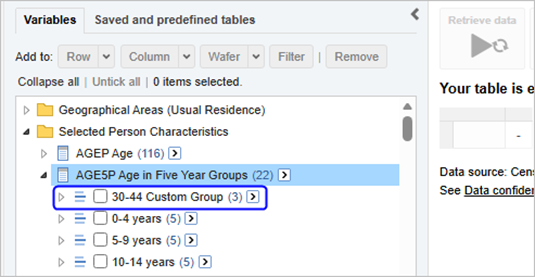
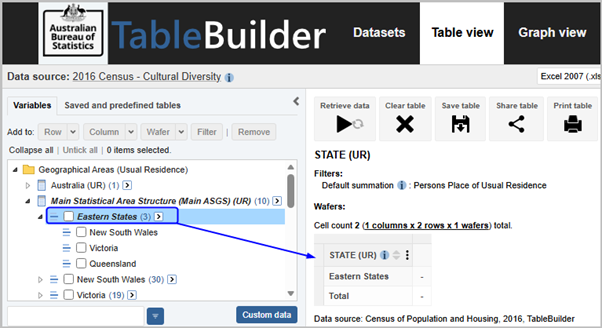
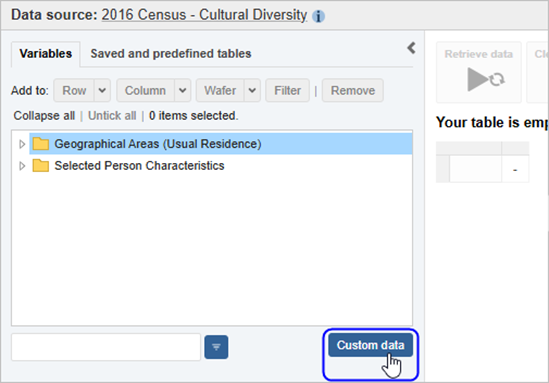
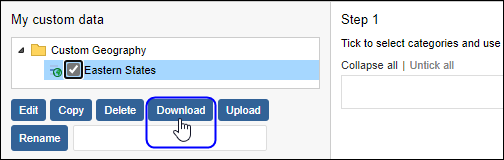
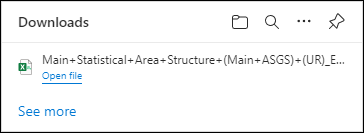
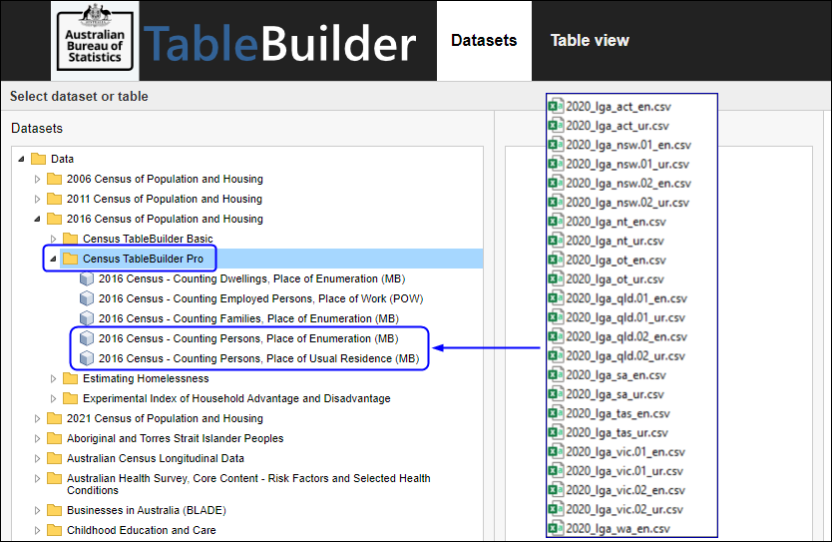
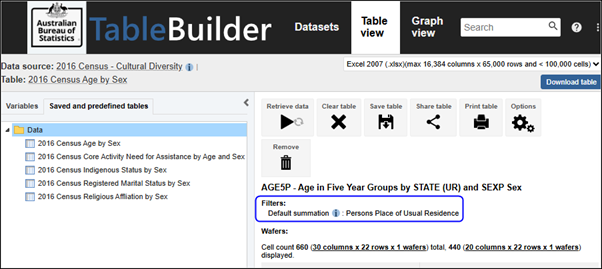
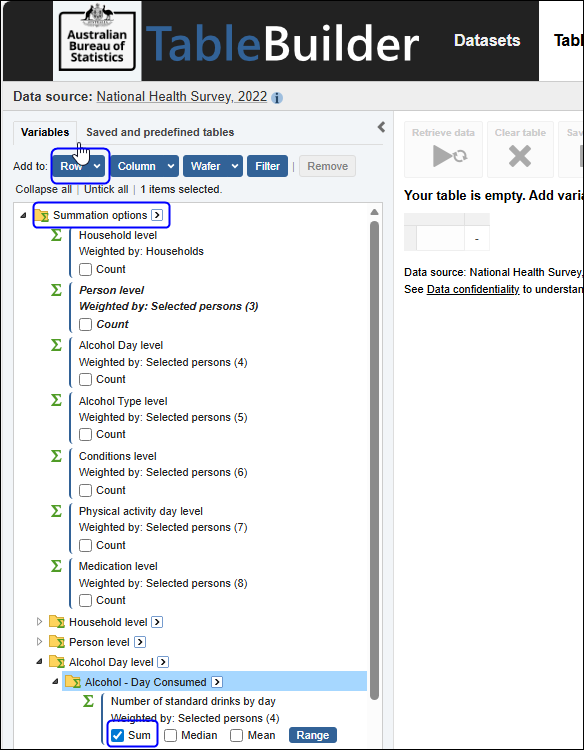
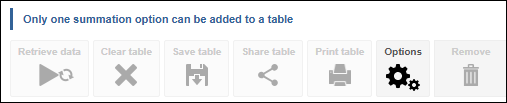
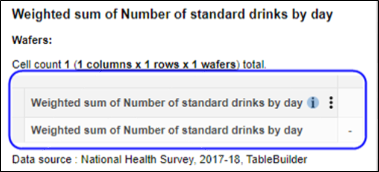
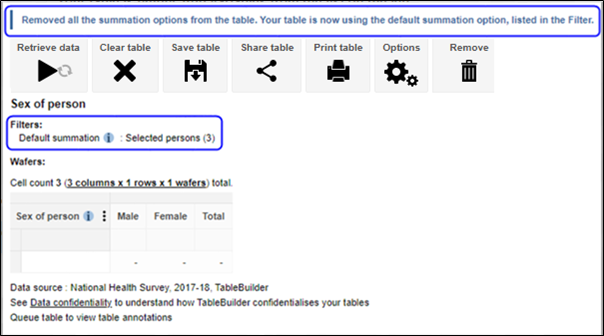
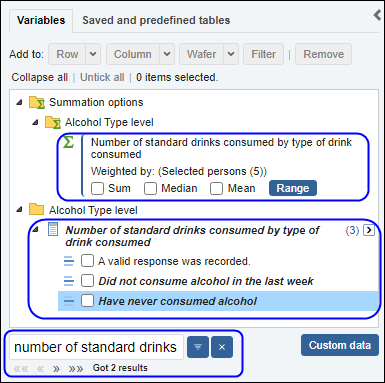
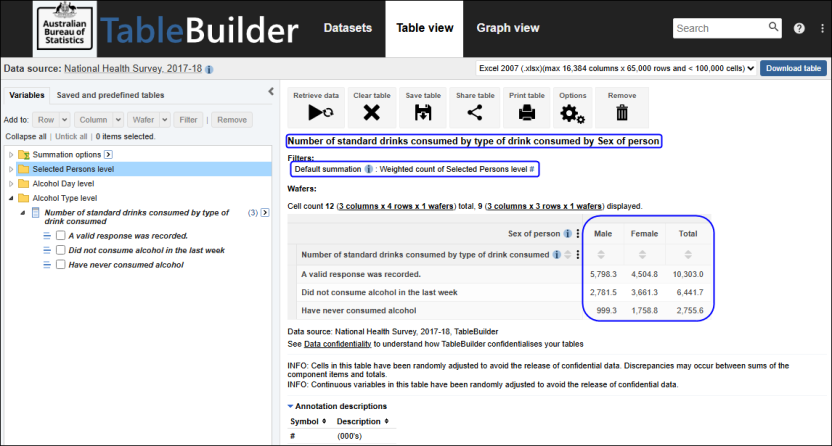
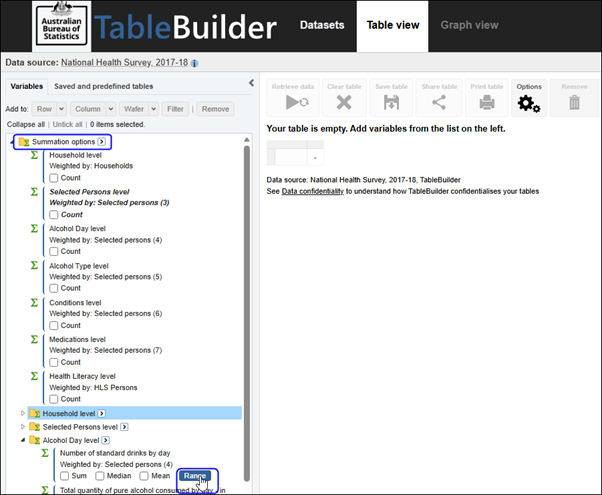
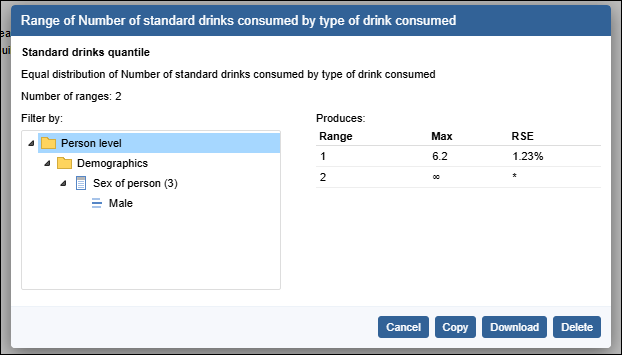
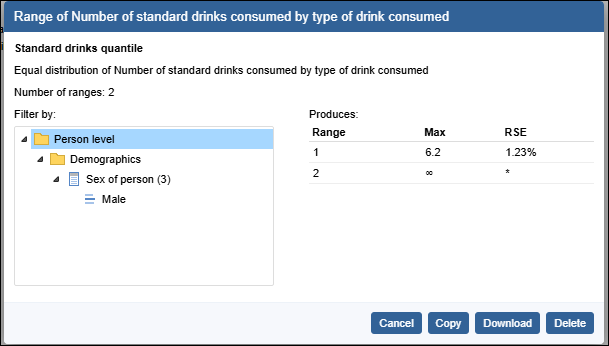
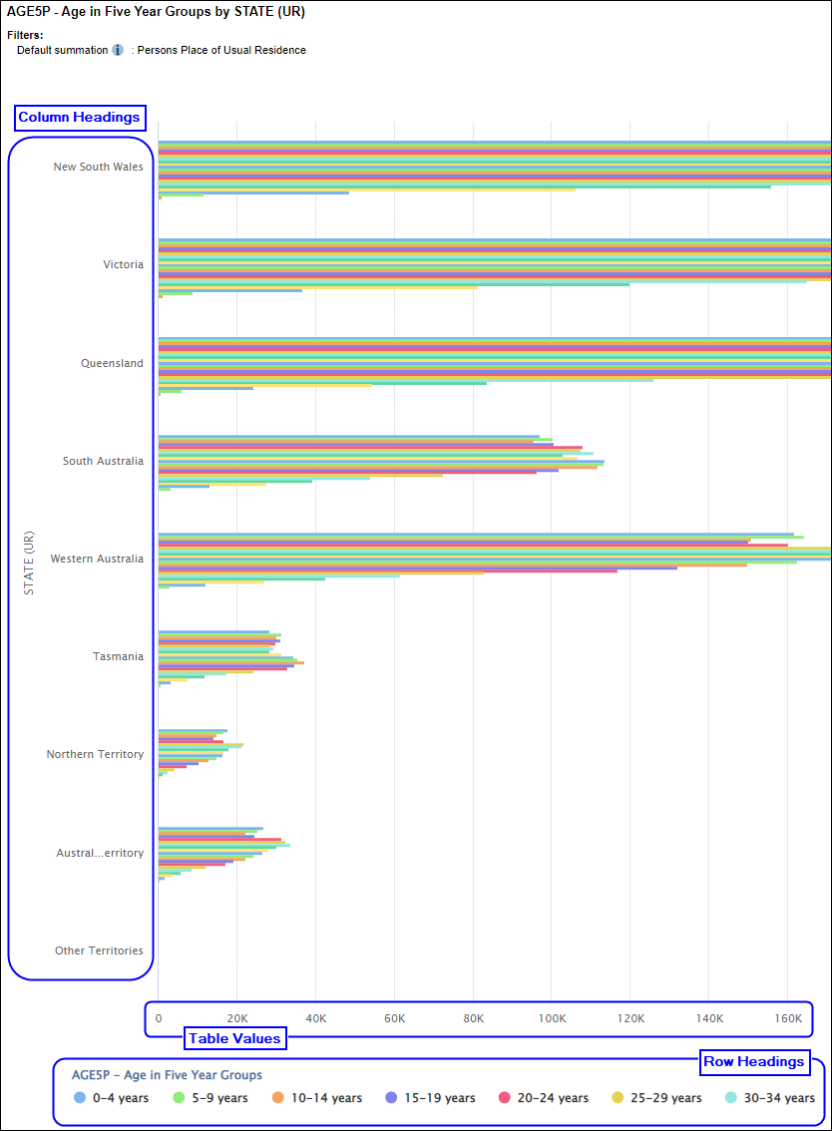
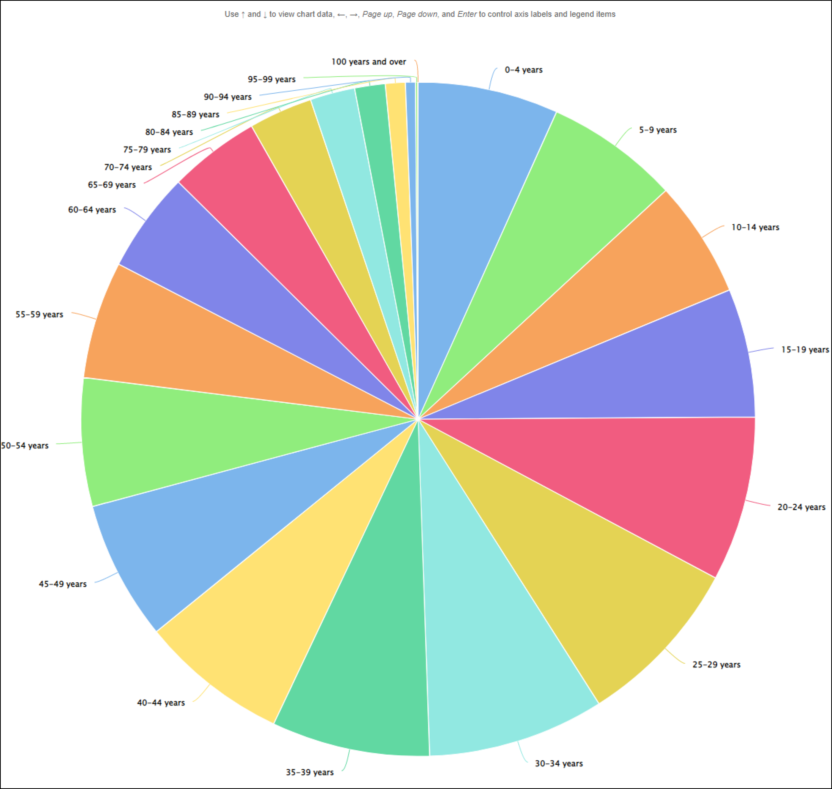
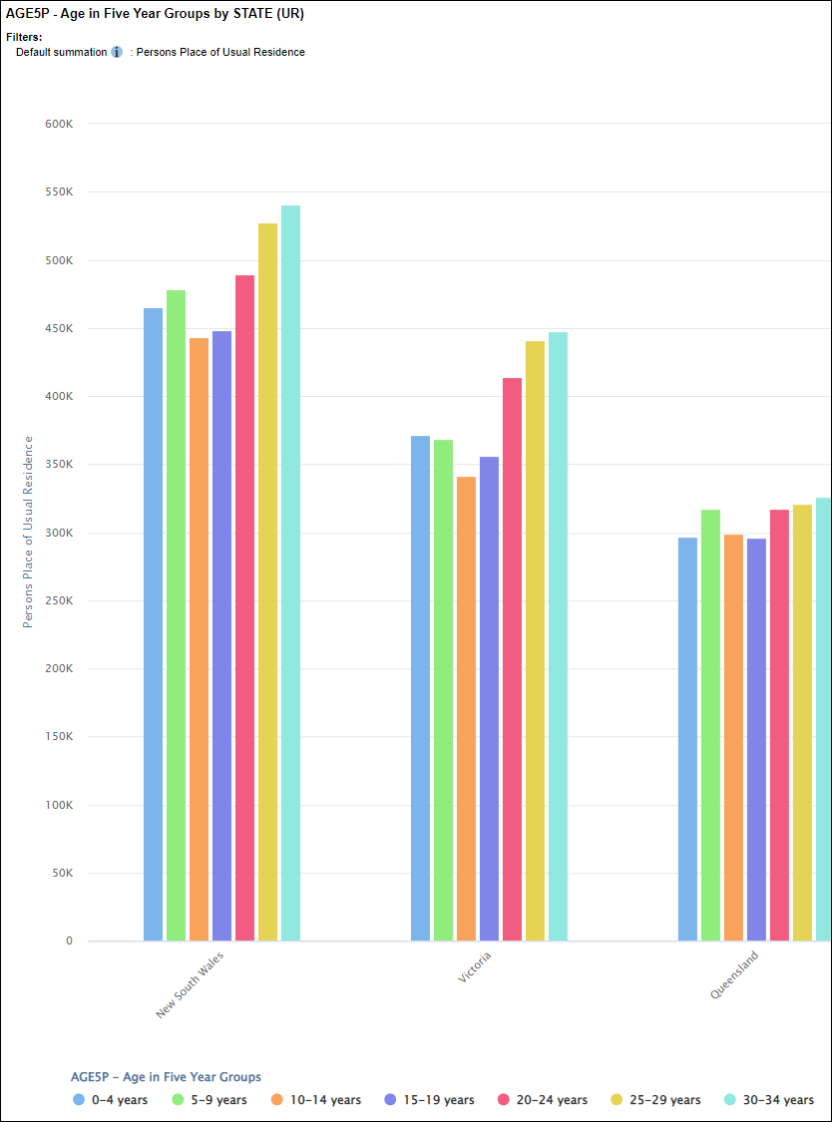
| Jobs and Income of Employed Persons, 2022-23 | Jobs and Income of Employed Persons provides statistics from the Longitudinal Employer Employee Database (LEED) to enable simultaneous analysis of met supply and demand in the Australian labour market. The LEED is a cross-sectional database, which uses administrative tax data to incorporate information from all employees and employers in Australia. From 2022-23, data on migrants has been linked to the LEED and a selection of variables are available in this microdata product. | Data items | 18/12/2025 |
| Retirement and Retirement Intentions, 2014-15 to 2022-23 | Provides a range of information relating to changes in retirement trends over time, factors which influence retirement, and the income arrangements made by retirees and potential retirees for their retirement. | Data items | 16/04/2025 |
| Labour Force Status of Families, 2005 to 2025 | Enables detailed analysis of how families engage with the labour market and provides statistics on broad family dynamics including the number and age of children in the household. | Data items | 23/10/2025 |
| Labour Force Survey, 2006-2026 | Enables analysis of the social and economic aspects of labour market engagement over time using monthly Labour Force Survey data. Provides high-frequency detailed statistics on the labour force, such as employment, hours worked, under-utilisation, unemployment, duration of job search and reasons not in the labour force. Time span: August 2006 to January 2026. | Data items | 19/03/2026 |
| Characteristics of Employment, 2014-25 | Weekly earnings of employees, casual workers, independent contractors, trade union membership, labour hire, job flexibility, job security. | Data items | 18/12/2025 |
| Jobs and Income of Employed Persons, 2021-22 | Jobs and Income of Employed Persons provides statistics from the Longitudinal Employer Employee Database (LEED) to enable simultaneous analysis of met supply and demand in the Australian labour market. The LEED is a cross-sectional database, which uses administrative tax data to incorporate information from all employees and employers in Australia. From 2019-20, data on migrants has been linked to the LEED and a selection of variables are available in this microdata product. | Data items | 13/12/2024 |
| Barriers and Incentives to Labour Force Participation, Retirement and Retirement Intentions, 2023-24 | Provides detailed information on characteristics of people who are not participating, or not participating fully, in the labour force and the factors that influence them to join or leave the labour force, and on information on retirement trends, the factors which influence decisions to retire, and the income arrangements that retirees and potential retirees have made to provide for their retirement. | Data items | 13/12/2024 |
| Barriers and Incentives to Labour Force Participation, Retirement and Retirement Intentions, 2018-19 | Provides detailed information on characteristics of people who are not participating, or not participating fully, in the labour force and the factors that influence them to join or leave the labour force, and on information on retirement trends, the factors which influence decisions to retire, and the income arrangements that retirees and potential retirees have made to provide for their retirement. | Data items | 28/08/2020 |
| Jobs in Australia, annually 2011-12 to 2018-19 | Jobs in Australia provides statistics from the Longitudinal Employer Employee Database (LEED) to enable simultaneous analysis of met supply and demand in the Australian labour market. The LEED is a cross-sectional database, which uses administrative tax data to incorporate information from all employees and employers in Australia. | Data items | 17/12/2021 |
| Jobs and Income of Employed Persons, 2019-20 | Jobs and Income of Employed Persons provides statistics from the Longitudinal Employer Employee Database (LEED) to enable simultaneous analysis of met supply and demand in the Australian labour market. The LEED is a cross-sectional database, which uses administrative tax data to incorporate information from all employees and employers in Australia. From 2019-20, data on migrants has been linked to the LEED and a selection of variables are available in this microdata product. | Data items | 31/05/2023 |
| Jobs and Income of Employed Persons, 2020-21 | Jobs and Income of Employed Persons provides statistics from the Longitudinal Employer Employee Database (LEED) to enable simultaneous analysis of met supply and demand in the Australian labour market. The LEED is a cross-sectional database, which uses administrative tax data to incorporate information from all employees and employers in Australia. From 2019-20, data on migrants has been linked to the LEED and a selection of variables are available in this microdata product. | Data items | 13/03/2024 |
| Labour Force Status of Families, annually 2009-2018, quarterly from March 2019 | Enables detailed analysis of how families engage with the labour market and provides statistics on broad family dynamics including the number and age of children in the household. | Data items | 11/10/2021 |
| Participation, Job Search and Mobility, annually from 2015 | Provides statistics relating to people looking for work, finding work, losing jobs, changing jobs, or the reasons why people are not working or looking for work. | Data items | 9/07/2024 |