| Scope | Collection method | Geographic coverage |
|---|---|---|
Detailed information is collected from: | - Personal visits to households
| The data is available at the national level and at the state level for New South Wales, Victoria, Queensland and Western Australia. Some data is available for other states and territories, but this may be limited due to standard error and confidentiality constraints. |
Survey responses were collected for 65,805 people: |
Overview
How the data is collected
Scope
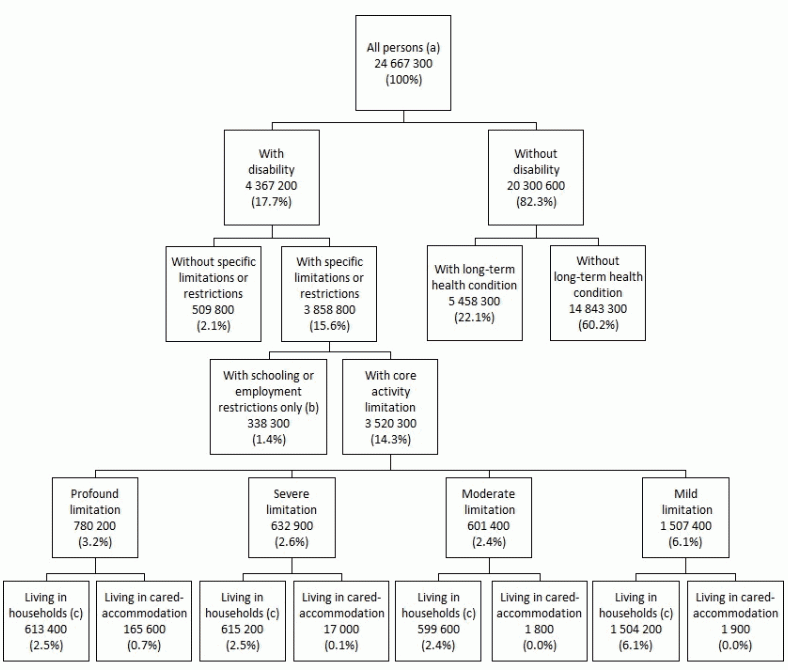
The ABS collected detailed information from three target populations:
- people with disability
- older people (those aged 65 years and over)
- carers of people with disability or a long-term health condition or older people.
A small amount of information was collected about people not in these populations, so the demographic and socio-economic characteristics of the three target populations can be compared with the general population.
The scope of the survey was people in urban and rural areas in all states and territories, living in either:
- private dwellings and self-care retirement villages; or
- health establishments that provided long-term cared accommodation (for at least three months).
The survey excluded people living in:
- hotels, motels and short term caravan parks
- religious and educational institutions
- hostels for the homeless or night shelters
- gaols or correctional institutions
- staff quarters, guest houses, boarding houses or other long term accommodation
- very remote areas
- discrete Aboriginal and Torres Strait Islander communities.
It also excluded:
- some diplomatic personnel of overseas governments (who were also excluded from the Census and Australia's estimated resident population)
- people who did not usually live in Australia
- members of non-Australian defence forces (and their dependents) stationed in Australia
- visitors to private dwellings and self-care retirement villages (who could have been included at their own residence)
- people who were away at the time of the interview and for the rest of the interview period
The ABS applied rules to associate each person with only one dwelling to reduce the chance of them being selected for the survey more than once.
A survey in two parts
The ABS had two different ways of collecting information depending on whether people lived in:
- private dwellings such as houses, flats, home units, townhouses and self-care components of retirement villages (the household component); or
- hospitals, nursing homes, hostels and other homes for a period of three months or more (the cared-accommodation component).
For each part, a sample of addresses to be surveyed was developed.
In 2018, this was done using the Address Register for the first time. The Address Register was established by the ABS in 2015 as a comprehensive list of all physical addresses in Australia. It is a trusted and comprehensive data set of Australian address information. It contains current address details, coordinate reference (or “geocode”), and address use information for addresses in Australia.
How the household sample was developed
The sample for the household component was selected at random using a multi-stage area sample of addresses from the ABS's Address Register.
Since 2015 self-care retirement villages have been treated as private dwellings and included in the household component. In 2015 a separate sample of self-care retirement villages was selected, whereas in 2018, with the introduction of the Address Register, self-care retirement villages were able to be selected as part of the private dwelling sample.
How the cared-accommodation sample was developed
The ABS sent letters to all known health establishments in Australia that may provide long-term cared-accommodation. They were asked to complete an online form which collected:
- the name and role of a contact person for the establishment
- whether their establishment offered cared-accommodation to occupants on a long-term basis (for three months or more)
- the current number of occupants residing in cared-accommodation
- the type of establishment.
Health establishments providing cared-accommodation to residents for at least three months could be selected in the sample. The more long-term occupants an establishment had, the higher their chance of being selected. If a health establishment was selected, their contact person was asked to choose a random sample of occupants for the survey by following instructions the ABS provided.
Response rates
Households and cared-accommodation providers that were asked to participate in the survey did not always respond in full. Only full responses were included in the final data. In 2018, the household component of the SDAC exceeded the fully responding national target of 21,305 households. These tables show that there were full responses from:
- 21,983 households (79.7% of those contacted)
- 1,068 health establishments (90.9% of health establishments contacted).
Table 1.1 Household component, response rates
| Number | % | ||
|---|---|---|---|
| Fully responding | 21,983 | 79.7 | |
| Non response | |||
| Refusal | 1,352 | 4.9 | |
| Non response | 4,085 | 14.8 | |
| Part response | 153 | 0.6 | |
| Total | 5,590 | 20.3 | |
| Total | 27,573 | 100.0 | |
Table 1.2 Cared-accommodation component, response rates
| Number | % | ||
|---|---|---|---|
| Responding establishments | 1,068 | 90.9 | |
| Non-responding establishments | 107 | 9.1 | |
| Total | 1,175 | 100.0 | |
After removing people who didn't fully respond or who were outside the scope of the survey (described above), there was a final combined sample of 65,805 people comprising:
- 54,142 people from the household component
- 11,663 people from the cared-accommodation component
Household component
Collection method
From 29 July 2018 to 2 March 2019, trained interviewers visited the randomly selected households to conduct personal interviews, entering responses on a computer with special software. The interviewer first asked screening questions of a responsible adult to find out whether anyone in the household:
- had disability
- was aged 65 years or more
- provided care to another person (within or outside the household).
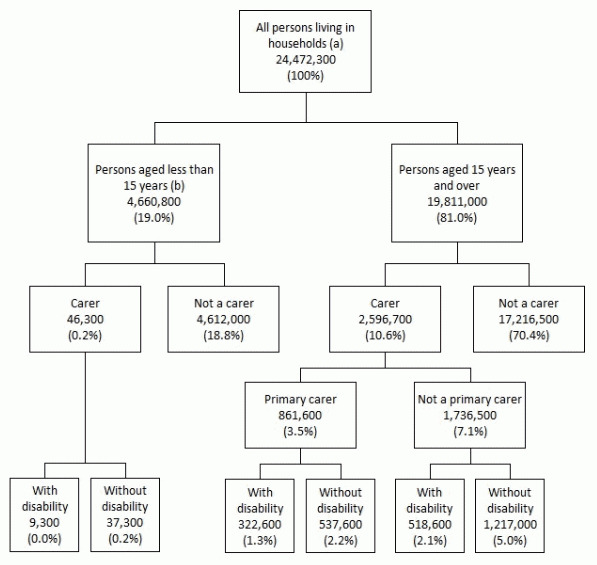
Interviews with people receiving care were also used to identify carers in that household.
Where possible, people with disability, aged 65 years or more or primary carers had a personal interview. To be identified as a primary carer, a person had to be providing the most informal help with a core activity to a person with disability. The core activities were communication, mobility and self-care. Some people were not interviewed directly, but had questions answered on their behalf (a proxy interview). Proxy interviews were done for:
- children under 15 years of age
- 15 to 17 year olds whose parent or guardian did not agree to them being personally interviewed
- people unable to answer for themselves due to illness, impairment, injury or language problems.
Interviewers asked people with disability about:
- what help they needed and received for mobility, self-care, communication, cognitive or emotional tasks, health care, household chores, property maintenance, meal preparation, reading and writing tasks, and transport activities
- their use of aids and equipment
- schooling restrictions, for those aged 5 to 20 years of age
- employment restrictions
- how satisfied they were with the quality and range of services available
- accessibility and discrimination related to disability
- whether they participated in the National Disability Insurance Scheme (NDIS)
- their internet use
- how they perceived their health and well-being
- their access and barriers to health care
- their level of social and community participation
- how safe they felt.
Interviewers asked people without disability aged 65 years and over about:
- how they perceived their health and well-being
- what help they needed and received for household chores, property maintenance, meal preparation, reading and writing tasks, and transport activities
- how satisfied they were with the quality and range of services available
- their internet use
- their level of social and community participation
- how safe they felt.
People who confirmed they were the primary carer of a person with disability were asked about:
- the type of care they provided
- the support available to them
- their internet use
- how they perceived their health and well-being
- their access and barriers to health care
- their level of social and community participation
- how the caring role had affected their own health, well-being and workforce participation
- their attitudes to, and experience of, their caring role.
Interviewers collected basic demographic and socio-economic information for everyone in the household, either from one responsible adult or personal interviews if preferred.
The interviewers used computers with software that reduced errors in data entry. It:
- prompted them to check least likely responses based on previous answers
- did not allow some contradictory responses
- had pick lists to prevent typing errors for some responses
- automatically converted some responses into codes.
Questionnaire
See the Data downloads section for the household questionnaire.
Prompt cards
See the Data downloads section for the prompt cards that interviewers used with respondents who were answering the questionnaire.
Cared-accommodation component
Collection method
Instead of interviewers visiting health establishments to personally interview a select number of occupants living in the health establishment, the contact officer who worked within the health establishment completed a separate questionnaire for each randomly selected occupant.
The range of information collected was narrower than in the household component as some topics were not:
- suitable for a contact officer to answer on behalf of occupants; or
- relevant to people in cared-accommodation.
Questionnaire
See the Data downloads section for the cared-accommodation questionnaire.
How the data is processed
Coding of long-term health conditions
The interview software automatically coded most long-term health conditions to a list of around 1,000 conditions. The rest were manually coded later. In 2018, the same code list was used as previous surveys.
Conditions could not always be reported at the full level of detail. Some conditions were grouped together under broader categories. Conditions were categorised based on the International Classification of Diseases: 10th Revision (ICD-10). There is more information about this in the 'Long-term Health Conditions ICD-10 Concordance' spreadsheet in the Data downloads section.
Editing
Once the ABS received the information collected from households and health establishments, it was checked very thoroughly to:
- minimise contradictory responses
- ensure relationships between pieces of information made sense (within acceptable limits)
- investigate responses that were unusual or close to the limits of what would be expected
- manually code responses not automatically coded during interviews
- fill in missing responses, where there was enough information to do so.
Estimation methods
As only a sample of people were surveyed, their results needed to be converted into estimates for the whole population. This was done with a process called weighting. Each person or household was given a number (known as a weight) to reflect how many people or households they represented in the whole population. A person's or household’s initial weight was based on their probability of being selected in the sample. For example, if the probability was 1 in 300, their initial weight would be 300 (meaning they represented 300 others). The initial weights were then adjusted to align with independent estimates of the in scope population, referred to as ‘benchmarks’. The benchmarks used additional information about the population to ensure that:
- people or households in the sample represented people or households that were similar to them
- the survey estimates reflected the distribution of the whole population, not the sample.
For example, the benchmarking meant that 0-5 year olds in Victoria in the survey represented other 0-5 year olds in Victoria, and males in large households in the survey represented other males in large households.
The household component was benchmarked to the estimated in scope population as at 30 November 2018. Information used to benchmark included:
- age (in 5 year age groups)
- sex
- usual place of residence
- household composition
- the Socio-Economic Indexes for Areas (SEIFA) index of relative socio-economic disadvantage national decile.
Previous iterations of SDAC were not weighted using SEIFA benchmarks. SEIFA benchmarks were added as an additional benchmark to the 2018 data when it was found that weighting without these benchmarks underestimated the number of people in low socio-economic areas.
The cared-accommodation component was benchmarked to the number of people living in long-term cared-accommodation in each state.
Using benchmarks means the estimates in SDAC match the composition of the whole population in scope of the survey. They do not match estimates for the total Australian population from other sources as these may include people living in non-private dwellings, very remote parts of Australia and discrete Aboriginal or Torres Strait Islander communities.
Estimates of the number of people in the population with a particular characteristic can be obtained by adding up the weights of all the people in the sample with that characteristic. Non-person estimates (eg number of health conditions) can be obtained by multiplying the characteristic with the weight of each reporting person and then adding up the results.
Age standardisation
Australia's age structure is changing over time. Some disabilities are more common in particular age groups. If the rates of those disabilities increase over time in a particular age group, it could just be because the proportion of people in that age group is increasing. Age standardisation removes age as a possible factor. If there is still an increase after doing age standardisation, that particular disability really is becoming more common.
The ABS used the direct age standardisation method with the standard population being the 30 June 2001 Estimated Resident Population. The standardisation has 5 year age group categories, up to 75 years and over.
The totals in Tables 1 and 2 present age standardisation by comparing rates over time.
Accuracy
Two types of error affect the accuracy of sample surveys: sampling and non-sampling error.
Sampling error
Sampling error is the difference between:
- estimates for a population made by surveying only a sample of people and
- results from surveying everyone in the population.
The size of the sampling error can be measured. It is reported as the Relative Standard Error (RSE) and 95% Margin of Error (MOE). For more information see the Technical Note.
In this publication, estimates with a RSE of 25% to 50% were flagged to indicate that the estimate has a high level of sampling error, and should be used with caution. Estimates with a RSE over 50% were also flagged and are generally considered too unreliable for most purposes.
Margins of Error are provided for proportions to help people using the data to assess how reliable it is. The proportion combined with the MOE shows the range likely to include the true population value with a given level of confidence. This is known as the confidence interval. People using the data need to consider this range if they are making decisions based on the proportion.
Non-sampling error
Non-sampling error can occur in any data collection, whether it is based on a sample or a full population count such as a census. Non-sampling errors occur when survey processes work less effectively than intended. Examples include errors in:
- reporting by respondents
- recording of answers by interviewers
- coding and processing of the data.
Non-response is another type of non-sampling error. This happens when people are unable to or do not respond, or cannot be contacted. Non-response can affect the reliability of results and can introduce a bias. The size of any bias depends on the rate of non-response and how much difference there is in the characteristics of people who responded to the survey and those who did not.
The ABS used the following methods to reduce the level and impact of non-response:
- face-to-face interviews with respondents
- the use of proxy interviews when there were language difficulties, noting the interpreter was typically a family member
- follow-up of respondents if there was initially no response
- weighting to population benchmarks to reduce non-response bias.
Rounding
- Estimates in this publication have been rounded.
- Proportions are based on rounded estimates.
- Calculations using rounded estimates may differ from those published.
How the data is released
The results of the 2018 SDAC include a Summary of Findings and data cubes (presented in a spreadsheet format) which contain a broad selection of national estimates. Further data will be released in a range of formats including:
- detailed microdata to be released in the DataLab at the same time as the main publication
- a TableBuilder product (subject to the approval of the Australian Statistician) to be accessible via the ABS website using a secure log-on portal in late 2019
- a set of data cubes containing a broad selection of estimates for each state and territory (subject to standard error and confidentiality constraints) in early 2020
- a Confidentialised Unit Record File (CURF) (subject to the approval of the Australian Statistician) to be available for download in early 2020
- a number of supplementary themed publications, released progressively after the main publication
- tables produced on request to meet specific information requirements from the survey (subject to confidentiality and sampling variability constraints).
Data item list
For further information on the comparability of data items see the Data downloads section for the 2018 SDAC Data Item List.
Confidentiality
The Census and Statistics Act, 1905 authorises the ABS to collect statistical information, and requires that information is not published in a way that could identify a particular person or organisation. The ABS must make sure that information about individual respondents cannot be derived from published data. The ABS takes care in the specification of tables to reduce the risk of identifying individuals. Random adjustment of the data is considered the best way to do this. A technique called perturbation randomly adjusts all cell values to prevent identifiable data being exposed. These adjustments result in small introduced random errors, which often result in tables not being 'internally consistent' (ie interior cells not adding up to the totals). However, the information value of the table as a whole is not impacted. This technique allows the production of very large/detailed tables valued by clients even when they contain cells of very small numbers.
Perturbation was applied to published data from 2012 onwards. Data from surveys before 2012 have not been perturbed, but have been confidentialised by suppressing cells if required.
Concepts, sources and methods
Main concepts
The main concepts of this survey are:
- disability
- long-term health condition
- specific limitation or restriction
- core activity limitation and levels of restriction
- need for assistance.
How the data is structured
Tables and other information presented in this publication were produced from over 1200 data items. Some of these data items came from responses to individual survey questions. Others were derived based on answers to multiple questions. For example the item 'disability status' was derived from responses to approximately 80 questions. All data items were stored in the output data file, which was very similar to the file from the 2015 survey. The data was structured into the following 10 levels:
| Level | Information type |
|---|---|
| 1. Household | Household size, structure and income details |
| 2. Family | Family size and structure, including whether there was a carer and/or a person with disability in the family |
| 3. Income unit | Income unit size and whether there was a primary carer in the income unit |
| 4. Person (the main level) | Demographic, socio-economic and health related characteristics of the survey respondents |
| 5. All conditions | Long-term health conditions reported in the survey |
| 6. Restrictions | Restrictions reported in the survey |
| 7. Specific activities | How much support people needed to perform specific activities, such as moving about their place of residence |
| 8. Recipient | Respondents who needed help or supervision with everyday activities because of their age or disability, whose carers lived in the same household. |
| 9. Broad activities | How much support people needed to perform tasks at the broad activity level (eg mobility, communication) |
| 10. Assistance providers | People providing assistance to others because of age or disability, including the types of assistance they provided |
The first four levels are in a hierarchical relationship: a person is a member of an income unit, which is a member of a family, which is a member of a household. Levels five to nine are in a hierarchical relationship with the person level and level ten is in a hierarchical relationship with level nine. All person and lower level records link to a household, family and income unit record. However, lower level records only exist where the person is in the relevant population.
Data about households and families are contained as individual characteristics on person records. A full list of the output data items available from this survey can be accessed from the 2018 SDAC Data Item List.
Interpretation of results
Measuring disability
Disability is a difficult concept to measure because it depends on a person's perception of their ability to perform a range of day-to-day activities. Factors discussed below should also be considered when interpreting results. Wherever possible results were based on personal responses – people answering for themselves. However, in some cases information was provided by another person (a proxy), and these answers may have differed from how the selected person would have responded. The concepts of 'need' and 'difficulty' were more likely to be affected by proxy interviews.
Certain conditions may not have been reported because:
- there was sensitivity about them (eg alcohol and drug-related conditions, other mental health conditions)
- they were episodic or seasonal (eg asthma, epilepsy) so not present at the time of the survey
- a person reporting for someone else was unaware of a condition they had (eg mild diabetes) or did not know the correct term for it.
As certain conditions may not have been reported, data collected from the survey may have underestimated the number of people with one or more disabilities.
The need for help may have been underestimated. Some people may not have admitted to needing help because they wanted to remain independent, or did not realise they needed help because they had always received it.
People have different ways of assessing whether they have difficulty performing tasks. Some might compare themselves to others of a similar age, others might compare themselves to their own ability when younger.
The different collection methods used (personal interview for households, and administrator completed questionnaire for cared-accommodation) may have affected the reporting of need for assistance with core activities. This would have affected measures such as disability status. This would have had a bigger impact on the older age groups because they were more likely to be in cared-accommodation.
National Disability Insurance Scheme
Since 2015, the SDAC has collected information about National Disability Insurance Scheme (NDIS) participation for future use in comparing outcomes for NDIS participants compared with those who are not participants. At the time of 2018 enumeration, the NDIS was still rolling out in many jurisdictions and therefore the data reflects only those who reported receiving an agreed package of support through NDIS at the time of enumeration. Given this, the ABS would advise users to carefully consider these limitations if looking to use NDIS data in any analysis, especially when analysing data at finer levels. The NDIS variable has not been included in the Summary of Findings tables or analysis.
Self-completed forms for primary carers
In this survey, people who confirmed they were the primary carer of a person with a disability were also asked to complete a paper questionnaire which asked about their attitudes to, and experience of, their caring role. Allowing them to complete the questionnaire privately rather than responding verbally to interviewer questions was considered the best way to get accurate responses to these more personal questions.
Some data items related to primary carers were derived from questions answered in this self-completion questionnaire. In 2018, approximately 10% of the primary carer population did not complete the self-completion questionnaire. Non-responses could have caused biased results if those who responded to the self-completion questionnaire were in some way different to the total population of primary carers. Analysis of 2018 data showed that there were no statistically significant differences between the characteristics of all primary carers and those who responded to the questionnaire.
Non-responses to the self-completed form were excluded when proportions were calculated for primary carer data items using questions from this form.
Standards and classifications
Classifications
Long-term health conditions described in this publication were categorised to an output classification developed for the SDAC, based on the International Classification of Diseases: 10th Revision (ICD-10). For a concordance of codes used in the 2018 SDAC with the ICD-10 please refer to the Long-term Health Conditions ICD-10 Concordance spreadsheet. This classification, with some minor amendments, has been used since the 2003 survey.
- Country of birth was classified according to the Standard Australian Classification of Countries (SACC), 2016 (cat. no. 1269.0).
- Main language spoken at home was classified according to the Australian Standard Classification of Languages (ASCL), 2016 (cat. no. 1267.0).
- Education data were classified according to the Australian Standard Classification of Education (ASCED), 2001 (cat. no. 1272.0).
- Occupation data were classified according to the Australian and New Zealand Standard Classification of Occupations (ANZSCO) 2013 (cat .no. 1220.0).
- Industry data were classified according to the Australian and New Zealand Standard Industrial Classification (ANZSIC), 2006 (cat.no. 1292.0).
- Remoteness areas were classified according to the Australian Statistical Geography Standard (ASGS): Volume 5 - Remoteness Structure, July 2016 (cat. no. 1270.0.55.005).
Socio-economic Indexes for Areas (SEIFA)
Socio-economic Indexes for Areas (SEIFA) is a suite of four summary measures that were created from 2016 Census information. Each index summarises a different aspect of the socio-economic conditions of people living in an area. The indexes provide more general measures of socio-economic status than is given by measures such as income or unemployment alone.
SEIFA uses a broad definition of relative socio-economic disadvantage in terms of people's access to material and social resources and their ability to participate in society. While SEIFA represents an average of all people living in an area, it does not represent the individual situation of each person. Larger areas are more likely to have greater diversity of people and households.
For more detail, see the Census of Population and Housing: Socio-Economic Indexes for Areas (SEIFA), Australia, 2016 (cat. no. 2033.0.55.001).
History of changes
The 2018 SDAC is the ninth national survey, following similar surveys in 1981, 1988, 1993, 1998, 2003, 2009, 2012 and 2015.
Comparability with previous Surveys of Disability, Ageing and Carers
Most of the content of the nine disability surveys conducted by the ABS is comparable. There are differences, however, as more recent surveys have tried to get better coverage of disability and of specific tasks and activities previously thought to be too sensitive for a population survey. For further information on the comparability of data items and new data items see the 2018 SDAC Data Item List.