CHAPTER 3 HOW SEIFA IS CONSTRUCTED
INTRODUCTION
SEIFA indexes are created by combining information selected from the Census. Each piece of information is first selected on the basis of a concept of relative socio-economic disadvantage; and then turned into a 'variable' which can be used in the index creation process. This chapter looks at the concept behind the indexes, how the information is selected and what a typical variable looks like. This chapter also looks briefly at principal components analysis.
- THE CONCEPT OF SOCIO-ECONOMIC DISADVANTAGE
- INFORMATION SELECTION
- VARIABLE CREATION
- PRINCIPAL COMPONENTS ANALYSIS (PCA)
- EXAMINING THE RELATIONSHIP BETWEEN VARIABLES AND SCORES
THE CONCEPT OF SOCIO-ECONOMIC DISADVANTAGE
The concept of relative socio-economic disadvantage is neither simple nor well-defined. Based on international research and also on information collected in Census, we broadly define relative socio-economic advantage and disadvantage in terms of people's access to material and social resources, and their ability to participate in society. However, there are some important things to remember about the concept of relative socio-economic disadvantage.
Disadvantage has no perfect measure
No single measure can fully capture the concept of relative socio-economic disadvantage. It is important to be aware that the information used to create SEIFA is only related to disadvantage and does not perfectly measure disadvantage. For example, information on low income is used in three of the indexes because it is related to disadvantage; and high income is related to advantage or lack of disadvantage. However, low income does not guarantee disadvantage; it is only an indicator that a household might be disadvantaged. Some low income households may have access to other economic resources such as wealth or support from other households, or their low current income could reflect a temporary situation, such as a business or investment start up.
SEIFA is a summary measure
A SEIFA index summarises the characteristics of people and households within an area. A SEIFA score therefore reflects this group of people as a whole; it does not reflect any one person or household within that area. In addition, areas are often quite diverse and so can have both high income and low income households, for example. It is possible for a high income household to reside in a relatively disadvantaged area.
SEIFA is a relative measure
It is incorrect to state that an area with a low SEIFA score is disadvantaged. It can only be determined that an area is disadvantaged relative to other areas.
Disadvantage is a social construct
Disadvantage is defined by the society in which we live. While an area could be disadvantaged compared to another area within Australia, it could be more advantaged than other parts of the world.
It is also difficult to create a single measure which captures disadvantage across a diverse country like Australia. The concept of disadvantage can have a slightly different interpretation for different regions and sub-cultures. For example, in some ways regional areas may be considered more disadvantaged than metropolitan areas due to their remoteness. SEIFA does not focus on disadvantage in terms of what it means to a person living in the city, nor solely to a person living in regional areas. Because SEIFA is a general index, it aims to measure relative socio-economic disadvantage in terms of what it means to everyone in Australia.
Disadvantage is subjective
What does it mean to be disadvantaged? Every person you ask is likely to give a different response, basing their answers on their own perceptions and different criteria. For example, most will agree that income has an important relationship with disadvantage. However, some may argue that poor access to health care services or education is a greater indicator of disadvantage than low income.
Because there are many dimensions of socio-economic disadvantage, disadvantage is difficult to measure. SEIFA is limited to reflecting only information that is measured in the Census.
The international and ABS approaches
International and Australian studies have looked at similar concepts, including social capital, deprivation, poverty, well-being and social exclusion. While these concepts are related to socio-economic disadvantage, they are also different. In addition, some indexes have been developed based on these different concepts, such as the New Zealand Index of Deprivation. Employment, education and financial well-being are three dimensions common to most of these indexes. Other dimensions commonly included are unemployment, housing stress, overcrowding, home ownership, family support, family breakdown, family type, lack of wealth (no car or telephone), low income, Indigenous status and foreign birth.
SEIFA aims to capture relative socio-economic disadvantage by selecting data based on these common dimensions. As discussed earlier, the ABS broadly defines relative socio-economic disadvantage in terms of people's access to material and social resources, and their ability to participate in society.
As there can be no one definitive measure of advantage/disadvantage, there are four separate indexes in SEIFA. As discussed in Chapters 1 and 2, each index aims to capture a different aspect of relative socio-economic disadvantage. Because each index uses different variables, an area can therefore have a different score for each index.
Importantly, any measure of disadvantage will only reflect the information from which it is made. This makes the variable selection process very important, as discussed in the 'Information selection and variable creation' section of this chapter.
INFORMATION SELECTION
Selection
Any measure of disadvantage will only reflect the information from which it is made, which makes the information selection process very important. SEIFA indexes are created by combining information selected from the Census. Information from the Census is first selected on the basis of the concept of relative socio-economic disadvantage defined earlier in this chapter. The appropriate Census data items are then turned into a 'variable', which are used in the index creation process.
Information selection
Information is taken only from the Census as this is the best source of detailed information within small geographic areas. However, this approach limits the range of information available.
Information was selected on the basis of association with relative disadvantage, rather than any assumption of cause and effect. For example, low income was selected because it is associated with relative disadvantage, not because it is either a 'cause' or an 'effect' of disadvantage.
Some information is included because of a direct association with relative disadvantage, such as low income. Other information is included because of an indirect association; this information acts as a proxy for important information that is unable to be captured using Census data. A good example is the variable measuring the proportion of people in an area who identify themselves as Indigenous. SEIFA includes this information as a proxy measure of relative disadvantage because it captures important information that is otherwise unavailable from the Census, such as relative health and life expectancy information.
In reality all data, both direct and indirect, provide a wealth of indirect information about relative socio-economic disadvantage. That is, in some way all included data acts as a proxy for relative disadvantage. In SEIFA, the indexes aim to explain relative disadvantage by measuring some common dimension underlying these proxies.(footnote 1)
Impact of PCA on selection
When selecting information, it is important to consider the method used to create the indexes. The method used, principal components analysis (PCA)(footnote 2) , creates a summary measure from a group of select variables. PCA assumes there is some common dimension underlying these variables, and creates a summary measure to capture this commonality. This summary measure represents a 'line of best fit' which is entirely dependent on the relationships (correlations) between the variables. Unlike some other methods, PCA
requires the variables to be correlated. It is actually the correlations that SEIFA is trying to capture, because this commonality among the variables is that which is deemed to measure relative socio-economic disadvantage. However, we need to make sure that any particular aspect of relative socio-economic disadvantage is not overrepresented as this could bias SEIFA.
SEIFA aims to measure relative socio-economic disadvantage using a select group of variables, each of which measures a different concept of relative disadvantage. Information is selected to capture an aspect of relative disadvantage, however the indexes can be biased if too many variables are included that measure the same aspect. Deciding whether a variable is too similar is not straightforward because, as discussed above, it is precisely the similarities between the information that SEIFA aims to capture. This issue is illustrated by the following examples.
- The Disadvantage index includes both a low-rent variable and a public-housing variable, even though many households within public housing also pay relatively low rent. It was decided that there was enough difference between the aspects of relative disadvantage captured by each variable (at an area-level) to include both.
- Some households have to access the private rental market until they are able to obtain public housing. Also, the Commonwealth Government provides rental assistance to eligible private renters. In SEIFA, these households are unable to be separated from other households in the private rental market.
Consistency and changes
While consistency across SEIFA releases is very important, changes were made where necessary or to improve the quality of the indexes. Refer also to Chapter 1 and the Technical Paper.
- Census information changes over time with new data items and improvements to existing variables. Some new data items were considered for inclusion in SEIFA, such as need for assistance with core activities. (footnote 3) Some SEIFA variables were re-specified due to changes to Census data items.
- Classification standards used by Census are updated over time. SEIFA variables were affected by changes to classification standards for occupation.
- Some SEIFA variables were redefined because society has changed. For example, access to broadband internet is considered an indicator of improved ability to participate in society. However, access to broadband internet was not collected in earlier Censuses.
- Some existing Census data items that were not previously included in SEIFA, or included only in one or two SEIFA indexes, were reconsidered for inclusion in the 2006 SEIFA indexes. For example, unemployment was introduced to the 2006 Index of Economic Resources.
- Important improvements to SEIFA were made, such as the use of equivalised household income, and counting people in their usual residence (rather than where they were on Census night).
Because the indexes are sensitive to changes, the information selection process is important.
VARIABLE CREATION PROCESS
The process of creating SEIFA variables is as follows:
Step 1: Information selection
As discussed, Census data items that represent an aspect of relative socio-economic disadvantage were selected. The information may relate to individuals, families or households.
Step 2: Variable specification
For the purposes of the PCA method, all SEIFA variables were expressed as proportions. Every proportion was specified using past specifications and advice from the ABS Census area and relevant subject matter areas. Many decisions were made for every variable specified.
For example, the variable LOWRENT was defined as the proportion of households paying rent who pay less than $120 per week. The numerator and denominator for this variable was specified as:
the number of renting occupied private dwellings who pay less than $120 per week rent (exclude rent = $0), divided by
the number of renting occupied private dwellings with stated rent.
This example illustrates a number of the issues that arose when specifying variables. In order to make these decisions, it was important to consider the specific concept the variable was aiming to capture and the impact of the alternative choices. Some of the issues in this example include:
- Whether to count people, families or dwellings. The proportion of people (in low rent households) can be different to the proportion of dwellings (that pay low rent).
- Whether the denominator should include the number of rented dwellings or the number of total dwellings. It is important to consider the impact of this decision for different situations, such as the case of a CD with no rented dwellings.
- Whether the denominator should include dwellings who did not state their rent payments. In this example, only those dwellings that stated their rental payments were included.
- Whether to include zero rent payments in the numerator. In this example, rented dwellings paying zero rent were not included in the numerator, because these dwellings tended to have different characteristics to dwellings paying low rent.
- How to determine the cut-off values. In this example, rental payment of $120 per week was chosen because this represented 20 per cent of rented dwellings. This cut-off does not represent any presumed level of absolute disadvantage; it was selected to reflect the concept of relative disadvantage.
- While people could be counted within their CD of usual residence (if this information was provided), dwelling information was only recorded if at least one person was at home on Census Night. If the usual residents were elsewhere on the night (on holidays, for example), then no-one would have been at home to record that dwelling's characteristics.
Step 3: Missing values
All surveys and censuses contain missing information, either due to non-response or due to responses being illegible. While Census data processing imputed data for age, sex, marital status and usual residence, other information was coded to 'Not stated'. However, some data items, such as income, were considered crucial to the construction of SEIFA indexes. As discussed in Chapter 2, a SEIFA score was not created for a CD that had a significant proportion of missing data for these important variables. Therefore, if a CD had a high level of non-response for an important variable, then that CD was excluded from the analysis and no SEIFA scores were created for that CD. In some instances, such as the previous example, the variables themselves were specified to exclude a dwelling or person if some information was not stated.
Step 4: Data extraction
Data was extracted from the Census and used to create the numerators and denominators according to the SEIFA variable specifications.
Step 5: Checking
The numerators and denominators were checked against published State totals (where possible) or by being re-created using a different methodology.
Step 6: Variable creation
Variables were created from the numerators and denominators. Summary statistics were created for each variable so that the variable distributions could be examined.
PRINCIPAL COMPONENTS ANALYSIS (PCA)
Once the variables have been created, they are used to create a score for every CD. Combined, this set of CD scores is called a SEIFA index.
This section briefly explains the method used to create the SEIFA indexes, called Principal Components Analysis (PCA). PCA is discussed further in the Glossary and in the Technical Paper. These summaries are in no way intended to replace a proper technical understanding of this technique.
The concept of relative socio-economic disadvantage is difficult to capture because it has many dimensions which are hard to measure. In SEIFA, PCA is used to create a summary measure of a group of characteristics. For example, the Index of Relative Socio-economic Disadvantage is a summary measure of a group of characteristics related to relative socio-economic disadvantage. There is no preconception about how important each characteristic is to the index. The importance of a characteristic is determined by the relationships between the characteristics themselves across all the areas. PCA uses these complex relationships to create a 'weight' for each characteristic. A SEIFA score can then be calculated for an individual area using that area's own characteristics and these weights.
EXAMINING THE RELATIONSHIP BETWEEN VARIABLES AND SCORES
Analysis of the variable distributions
This section aims to further explain the relationship between variables and CD scores.
Because the SEIFA variables were expressed as proportions, they could only have a value between zero and one. For example, if a CD has 100 dwellings with 20 earning low income, then the Low Income variable value for that CD would equal 20/100 = 0.20. Each CD would therefore have a set of values, one for every variable, between zero and one.
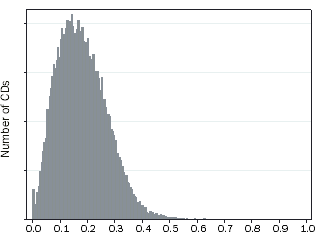
One way to describe a variable is to graph the value for every CD along a zero-one axis. This is called the variable's distribution. This distribution shows how many CDs have a variable value of 0.10, how many have a value of 0.11 and so on. Most of the 2006 SEIFA variables have a similar distribution to that shown in figure 3.1. These distributions are generally 'right-skewed' and have a low average value with a long right tail. The skewness of these variables is expected, for example many CDs have a low proportion of rented dwellings paying low rent, but some CDs have a high proportion.
The variables with the greatest skewness are: low rental payments; high rental payments; Indigenous status; no schooling; overcrowding; current university attendance; and renting from government or community organisation. These variables were also highly skewed in 2001.
Some variables have a more 'normal' distribution, which looks more symmetrical: no post-school qualifications; no year 12 education, no internet connection; mortgage home ownership; outright home ownership. The spare bedroom variable is left-skewed. This was a similar feature of the 2001 SEIFA variables.
Figure 3.1 Typical Variable Distribution, All CDs
Variable distributions and SEIFA scores
While figure 3.1 describes a variable's distribution for all CDs, we can also look at a variable's distribution for only those CDs with a low (or high) SEIFA score. For example, the distribution of the Low Income variable for CDs in Decile 1 (most disadvantaged) can be compared to the distribution of CDs in the Decile 10 (most advantaged).(footnote 4) Figure 3.2 compares the distribution of Low Income variable values for CDs in Deciles 1 and 10 (for the Index of Relative Advantage and Disadvantage).(footnote 5)
Figure 3.2 Low Income Variable distribution, Decile 1 and Decile 10
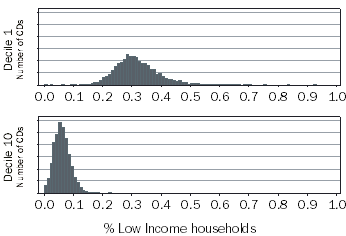
There are two important points to note:
- The average value for CDs in Decile 1 is high compared to Decile 10. This means that, on average, CDs in the most disadvantaged IRSAD decile have a higher proportion of low income dwellings, than CDs in the most advantaged IRSAD decile.
- An individual CD can still have a value very different to this average. For example, it is possible for an individual CD in the most disadvantaged decile to have a Low Income value similar to CDs in the most advantaged decile.
For comparison,
figure 3.3 shows these top and bottom decile distributions for the
High Income variable.
Figure 3.3 High Income Variable Distribution, Decile 1 and Decile 10
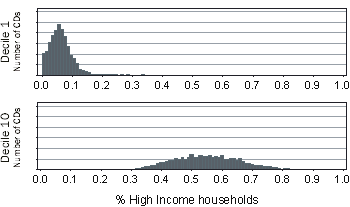
When comparing the
Low Income and
High Income distributions there are two more important points to note:
- The most disadvantaged decile CDs have a higher average value for the Low Income variable than they do for the High Income variable. This means that CDs with a relatively low SEIFA score will tend to have more low income dwellings than high income dwellings.
- SEIFA includes both Low Income and High Income variables because these are measuring different concepts.(footnote 6) For example, a CD with few low income dwellings may or may not have a high proportion of high income dwellings. Because a 'lack of low income dwellings' is different from 'many high income dwellings', both measures are included in SEIFA.
This section aimed to improve understanding of the relationship between the SEIFA index scores and the variables used to create them.
1 Because the data are proxies of relative disadvantage, it is difficult to use theory to predetermine appropriate weights for the data. <back
2 Please refer to the Principal Components Analysis (PCA) section later in this chapter, and to the Glossary for more information. <back
3 Please refer to the Glossary for further information on need for assistance with core activities. <back
4 Each decile contains 10% of all CDs. <back
5 These are Variable distributions, which are not to be confused with the SEIFA index distributions shown in Chapter 4. <back
6 Apart from the Disadvantage index, which includes only disadvantage variables. <back
 Print Page
Print Page
 Print All
Print All