GLOSSARY
Introduction
This Glossary is intended to briefly provide more detail on some of the terms and concepts used throughout this paper, but is not intended to replace a proper technical understanding of these concepts.
AGE-STANDARDISATION
Groups of people with different age structures tend to have different characteristics. For example, people in their 30s are likely to have a higher level of education than people in their 70s. Therefore, a neighbourhood with many people in their 30s is more likely to have a higher level of education in general than a neighbourhood with many people in their 70s. In SEIFA, a high level of education is considered to be relatively advantageous. This means that SEIFA ranks the younger neighbourhood as more advantaged, because of factors related to the different age profiles of the areas.
Age-standardisation could have been used to directly compare neighbourhoods with different age-profiles. However, age-standardisation was generally not used in SEIFA because the decision of whether to use age-standardisation depends on the type of using SEIFA. For different analyses, the link between age and education may or may not matter. For example, this link may not matter if your analysis considers education to be relatively advantageous irrespective of age. In this case, it would not be appropriate to age-standardise the education variable.
In SEIFA, adjusting for age was only undertaken for the variable measuring 'need for assistance'. This variable is directly linked to age because people are more likely to require assistance with core activities with increasing age. Some analysis would consider a 'need for assistance' to be important irrespective of age. However, SEIFA does not include people above the age of 70 in this measure, due to the impact this age group has on the variable.
ASGC
Australian Standard Geographic Classification. Refer to Geographies in the Glossary.
CENSUS COLLECTION DISTRICT (CD)
The CD is the smallest available area in the Australian Standard Geographic Classification (ASGC) and the smallest area for which the SEIFA indexes are available.(footnote 1) CDs are specifically designed for Census collection purposes and generally represent a reasonable workload for a Census collection officer. This means that CDs have different physical sizes and different population sizes. A CD might represent one apartment block in a city, or it might cover a vast outback area. CDs form the basis of all other geographies. Their boundaries can change for various reasons, including development on urban fringes, the implementation of higher density housing or changes in local government boundaries. There are 38,704 CDs in the 2006 ASGC (of which, 37,457 CDs were included in SEIFA). Refer to Geographies in the Glossary.
CENSUS DATA ITEM
Census collects information about a wide range of topics. This paper refers to this Census information as data items. For SEIFA, Census data items were used to create variables, which in turn, were used to create the SEIFA indexes.
CORRELATION
A correlation measures the linear relationship between two measures. A perfectly positive relationship would have a correlation of +1; a perfectly negative relationship would have a correlation of -1; no relationship would have a correlation of 0.
DECILE
Deciles divide a distribution into ten equal groups. In the case of SEIFA, the distribution of scores is divided into ten equal groups. The lowest scoring 10% of areas are given a decile number of 1, the second-lowest 10% of areas are given a decile number of 2 and so on, up to the highest 10% of areas which are given a decile number of 10.
To create the CD level deciles for example, because there are 37,457 CDs, the 3,746 CDs that have the lowest scores are given a decile number of 1, and so on.
Note that State deciles are also provided; refer to State decile in the Glossary for more information.
DISABILITY
Refer to Need for Assistance.
DISADVANTAGE
The terms 'disadvantage' and 'socio-economic disadvantage' are used interchangeably in this paper.
EQUIVALISED HOUSEHOLD INCOME
For the same standard of living, a larger household will require more income than a smaller household. For example, a two-person household will require more income to maintain the same standard of living as a single person household. Equivalence scales are used to adjust household income measures by the size of the household, so that all households can be more readily compared. The Census uses the 'modified OECD' equivalence scale. There are some issues for SEIFA, including:
- Equivalised household income is created only for private dwellings in the Census. Therefore SEIFA does not capture income for people living in non-private dwellings.
- Equivalised household income is not created for households with an adult who did not state their income or is temporarily absent, accounting for around 11% of applicable households.
There are other issues surrounding Census income measures, including:
- Equivalised household income includes wages, salaries and other income, such as dividends and rental assistance. Tax and superannuation contributions were not removed, therefore this is not a disposable income measure. Therefore, while some households pay less tax than other households, this cannot be captured in SEIFA.
- In the Census, income is measured after expenses from rent income or business/farm income were removed. These expenses may be significant for some households, and may result in low or even negative income.(footnote 2) Previous ABS research has found that these households tend to have higher net worth and household expenditure than other households with similar income levels.(footnote 3) Because these differences are not captured in the Census, they are not captured in SEIFA.
- Some households may mistakenly under-report their income, for example, by not including their pension or dividend income. This can lead to bias in SEIFA if this under-reporting is not evenly distributed throughout the population.
SEIFA is a general measure of relative socio-economic disadvantage that captures more information than income alone.
GEOGRAPHIES
The figure below compares the physical size of CDs, POAs, SLAs and LGAs for the Inner Sydney region. Note that this figure is indicative only, as these geographies can look quite different elsewhere in Australia. These maps were created using the 2006 Census Data by Location on the ABS website.(footnote 4)
Geographies, Inner Sydney
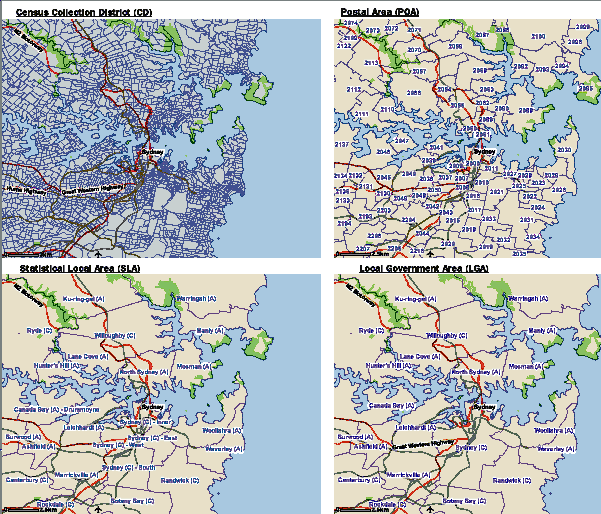
LOCAL GOVERNMENT AREA (LGA)
A Local Government Area (LGA) is an area under the responsibility of an incorporated local government or Indigenous council. LGA boundaries can be changed by the State/Territory government. Consequently the ABS adjusts its CDs and SLAs to match these boundaries. LGAs are equivalent to one or more SLAs. There are 676 LGAs in the 2006 ASGC (of which, 661 LGAs were included in SEIFA). Refer to Geographies in the Glossary.
MEAN
A mean is an average; a measure of central tendency of a distribution. A mean SEIFA score can be calculated by adding the value of all scores and dividing this by the number of scores being added.
NEED FOR ASSISTANCE
The disability variable, which is new to SEIFA in 2006, provides an indication of the physical or health aspects of relative socio-economic disadvantage. It is based on the new Census questions on need for assistance, which were developed to provide an indication of whether people have a profound or severe disability. People with a profound or severe disability are defined as those people needing help or assistance in one or more of the three core activity areas of self-care, mobility and communication, because of a disability, a long term health condition (lasting six months or more) or advanced age. For brevity in this paper, need for assistance is referred to using the term 'disability'. Note that the Census measure was designed to indicate the disability status of people in Australia according to geographic area, and for small groups within the broader population and is not a comprehensive measure of disability. Disability can limit employment opportunities, and consequently access to financial resources. For the purpose of indicating relative socio-economic disadvantage, we have limited the scope of the SEIFA disability variable to people aged under 70 (for more information see Appendix B of the Technical Manual).
NET WORTH
Refer to Wealth.
PERCENTILE
Percentiles divide a distribution into 100 equal groups. In the case of SEIFA, the distribution of scores is divided into 100 equal groups. The lowest scoring 1% of areas are given a percentile number of 1, the second-lowest 1% of areas are given a percentile number of 2 and so on, up to the highest 1% of areas which are given a percentile number of 100. SEIFA percentiles are provided to allow users to create their own groupings, such as quartiles (which contain 25% of CDs).
Note that State percentiles are also provided; refer to State Percentile in the Glossary for more information.
POPULATION WEIGHTING
SEIFA releases indexes for five different types of area: Census Districts (CDs), Statistical Local Areas (SLAs), Local Government Areas (LGAs), Postal Areas (POAs) and State Suburbs (SSCs). However, the SEIFA indexes can be used to create scores for other types of area. Because CDs form the basis of all of the standard geography boundaries, CD scores can be used to represent larger standard areas.
To create a score for a standard area, use a population weighted average of the CDs within the larger area. First, multiply each CD score by the number of people within that CD, and then divide by the total number of people within the larger area. These values can then be added together for all the CDs within the larger area, which is equal the score of the larger area. Population counts for CDs (the number of usual residents in the CD) have been provided with the index scores. The method outlined here is the method used to create the index scores for SLAs, LGAs, POAs and SSCs in SEIFA.
Once the scores have been created for the larger areas, the ranks, deciles and percentiles for these areas are then calculated. For example, once the SLA scores have been created, the SLAs are then ranked in order of their SLA score, and given a SLA rank number (between 1 and 1426). Then the SLAs are separated into ten groups and given a SLA decile number (between 1 and 10). The 10% of SLAs with the lowest SLA scores are given an SLA decile number of 1. That is, neither SLA ranks nor SLA deciles are created using population weighting directly from CD ranks or deciles.
It is important to note that, because of this method of construction, the distribution of scores for these larger geographic areas will not be a standard distribution. For example, the mean SLA scores will not be 1000, just as the standard deviations will not be 100. Also, the SLA deciles do refer to 10% of SLAs, and have only an indirect relationship to the CD deciles. An individual SLA will contain multiple CDs, with a range of CD scores, ranks and deciles that will be different to the SLA score, rank and decile.
Refer to the Technical Paper for further information on population weighting. Refer also to Geographies in the Glossary.
POSTAL AREA (POA)
Postal Areas are not an ASGC standard geography but are based upon one or more CDs in an attempt to match the postcodes used by Australia Post (at the time of the Census). Postcodes are used for delivering mail and in many cases have no specific boundaries. Because some surveys are based on postcode information rather than standard geographies, SEIFA is available in Postal Areas. However, SEIFA users need to be aware that Postal Areas and postcodes are not always good matches, and should use POAs with caution. For example, a CD can only be matched to single Postal Area even if it spans two postcodes. POAs cannot be matched at all to SLAs or LGAs, and may be smaller or larger than an SLA. The Postal Area number is the same as the matched postcode.(footnote 5) There are 2515 POAs in the 2006 ASGC (of which, 2474 POAs were included in SEIFA). Refer to Geographies in the Glossary.
PRINCIPAL COMPONENTS ANALYSIS
This section explains the method used to create the SEIFA indexes, called Principal Components Analysis (PCA). This brief overview is in no way intended to replace a proper technical understanding of this technique or its use, but will provide some guidance to facilitate the use of SEIFA.
OVERVIEW
The concept of relative socio-economic disadvantage is difficult to capture because it has many dimensions and because these dimensions are hard to measure. In SEIFA, PCA is used to create a summary measure of a group of characteristics. For example, the Index of Relative Socio-economic Disadvantage (IRSD) is a summary measure of a group of characteristics related to relative socio-economic disadvantage. There is no preconception about how important each characteristic is to the index. The importance of a characteristic is determined by the relationships between the characteristics themselves across all the areas. These complex relationships are used to create a 'weight' for each characteristic. A SEIFA score can then be calculated for an individual area using that area's own characteristics and the characteristic's weights.
FURTHER EXPLANATION
SEIFA uses PCA to create 'components'. A component captures a common relationship between a group of variables. (Refer to Chapter 3 for the creation of 'variables' from characteristics.)(footnote 6) The figure below shows an example of two variables that are combined to produce a component.(footnote 7) The First component is a 'line of best fit' through the variables. SEIFA uses only this First component because it captures the most information.(footnote 8) This component becomes our measure of socio-economic disadvantage. This component is used to calculate the 'weights' of each variable, which depend on the importance of each variable to the component. A SEIFA 'score' for every area in Australia can then be determined.
To determine a SEIFA score for an area, we first multiply the variable weights by the variable values for that area, and then add together. As discussed in Chapter 2, the distribution of scores were then 'standardised', so that the average score is 1000 and approximately two-thirds of the scores lie between 900 and 1100. Chapter 4 shows the standardised distributions of the scores for each index. Refer to Standardisation in the Glossary.
RANK
To determine the SEIFA rank, all the areas are ordered from lowest score to highest score. The area with the lowest score is given a rank of 1, the area with the second-lowest score is given a rank of 2 and so on, up to the area with the highest score which is given the highest rank (37,457 for a collection district (CD) index). While two areas may appear to have the same score due to rounding, every area has an individual score and an individual rank. However, caution should be used when separating areas with similar scores and ranks.
Note that State ranks are also provided; refer to State Rank in the Glossary for more information.
REGRESSION ANALYSIS
A popular analytical technique that, as for all techniques, relies an a set of assumptions. Refer to a statistical text for details.
SCORE
A SEIFA score is created using information about people and households in a particular area. A CD score is standardised against a mean of 1000 with a standard deviation of 100. This means that the average SEIFA CD score will be 1000 and the middle two-thirds of SEIFA scores will fall between 900 and 1100 (approximately). (Refer to Standardisation in the Glossary). A SEIFA score provides more information and is used for more sophisticated analysis. Ranks or deciles should be used for most analysis.
STATISTICAL LOCAL AREA (SLA)
Statistical Local Areas (SLAs) are made up of one or more CDs. There are 1426 SLAs in the 2006 ASGC (of which, 1390 SLAs were included in SEIFA). Refer to Geographies in the Glossary.
STANDARD GEOGRAPHIC AREAS
Refer to ASGC in the Glossary.
STANDARDISATION (AGE)
Refer to Age-standardisation in the Glossary.
STANDARDISATION
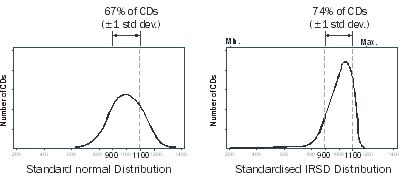
Using technical language, the standard distribution chosen for SEIFA has a "mean of 1000 and a standard deviation of 100". First, all of the CDs are ordered from the lowest to highest score. Second, all the scores are 'shifted' together so that the average area now has a new score of 1000. The areas are still in the same order, but they all have new scores spread around the average of 1000. The final stage changes how these scores are spread around the average. While they still remain in order, the scores are spread out (or condensed) so that two-thirds of the areas have 'standardised' scores somewhere between 900 and 1100; that is, approximately two-thirds of the scores lie within 100 either side of the average of 1000. This means that approximately 15% of CDs have a score lower than 900 with the remaining 85% of CDs having a score higher than 900. Approximately 85% of CDs have a score lower than 1100 with the remaining 15% of CDs having a score higher than 1100.
It is important to note that the distributions of the SEIFA indexes are not exactly a normal distribution even though they have been standardised. However the above proportions are roughly the same. The figure below compares a standard distribution to the standardised distribution of the Index of Relative Socio-economic Disadvantage (IRSD). The distributions of the other indexes are more symmetrical, as shown in Chapter 4.
Standardisation is useful when interpreting the scores and where the scores are used for more technical analysis. A different standard distribution could have been used, such as a mean of zero and a standard deviation of one. However, this would give some negative scores which may have been confusing and may have wrongly implied that areas with negative scores were 'disadvantaged'. When thinking about how to interpret standardised scores, it can be useful to bear in mind how the distribution would have looked if a different standard had been chosen.
Comparison of a Standard Distribution and the Standardised IRSD CD score distribution
STATE SUBURBS (SSC)
Like postal areas, State Suburbs (SSC) are not an ASGC standard geography. SSCs are based upon one or more CDs in an attempt to match suburbs (at the time of the Census). However, unlike postal areas, State Suburbs do not cover all of Australia, although most of the population is covered. Refer to the geography links in Chapter 7 for further information about the areas covered by State Suburbs. Because some surveys are based on suburb information rather than standard geographies, SEIFA is available in State Suburbs. (Note that SLAs in Brisbane and other major urban areas in Queensland, Darwin and Canberra are aligned closely with suburbs.) However, SEIFA users need to be aware that State Suburbs and suburbs are not always good matches, and should use SSCs with caution. For example, a CD can only be matched to single State Suburb even if it spans two suburbs. Not all CDs are matched to State Suburbs, and these CDs are given an Unclassified SSC code. SSCs cannot be matched at all to SLAs or LGAs. SSCs have both a code and a name. SSC names are based on the most recent gazetted locality boundaries current at the time of a Census. There are 8464 SSCs in the 2006 ASGC, however not all of these will be included in SEIFA. Refer to Geographies in the Glossary.
Note that the 2006 indexes for all geographies except SSC, were released on 26 March 2008.
STATE RANK, STATE DECILE, STATE PERCENTILE
SEIFA indexes are created for all areas within Australia. Therefore, the terms 'rank', 'decile' and 'percentile' used throughout this paper and the spreadsheets refer to the indexes based the number of areas across Australia. However, some users want to look only at areas within a certain state or territory. For these users, State ranks, State deciles and State percentiles have also been provided in the spreadsheets. These State numbers have not been created from scratch, but have instead been created using the Australia rank, decile and percentile as appropriate.
For example, the State ranks have been re-created for each state/territory, such that the lowest ranking CD in each of the eight states/territories is given a State rank of 1. This means, for example, that it is possible for a CD to have a rank of "79" (ranked 79th in Australia), and a State rank of "1" (ranked 1 in the state). On the spreadsheets, there will therefore be a total of eight State ranks equal to "1" (one for every state and territory). However, it is important to remember that a State rank of 1 only applies to that particular state/territory. That is, a CD with a State rank of "1" in NSW can have a very different SEIFA score (and level of relative socio-economic disadvantage) compared to a CD with a State rank of "1" in another state or territory.
Similarly, the State deciles have been created for each state/territory, such that the lowest 10% of areas in each of the eight States/Territories is given a State decile of 1. This means, for example, that it is possible for a CD to have a decile of "3", but a State decile of "1". A CD with a State decile of "1" in NSW can have a very different level of relative socio-economic disadvantage compared to a CD with a State decile of "1" in another state or territory.
Refer to Deciles, Ranks, Percentiles in the Glossary for more information.
VARIABLES
SEIFA uses principal components analysis to create scores using a range of measures related to the concept of relative socio-economic disadvantage. These measures, called variables, are created using data items from the Census.
WEALTH
Wealth is defined by different people in different ways. However, it is commonly interpreted as 'net worth', being a person's assets (such as shares and property) less their liabilities. In SEIFA, we extend this concept to include other aspects of wealth, such as access to lines of credit. However, the Census captures very little direct information on these measures. Therefore SEIFA uses proxy measures, such as ownership of an unincorporated enterprise.
1 Mesh Blocks are a smaller standard geographic area, however are currently experimental. <back
2 Negative and zero equivalised household income was measured in the Census. <back
3 Appendix 4 of Household Wealth and Wealth Distribution, Australia, 2003–04, cat. no. 6554.0. <back
4 www.censusdata.abs.gov.au <back
5 Because postcode are not named, Postal Areas are not given names (only the postcode number). <back
6 Because variables are proportions, an area's variable value must have a value between 0 and 1. The variable values themselves are standardised. <back
7 For example, these variables could be the low-income and no-schooling variables. SEIFA uses many variables, not just the two shown in this figure. <back
8 There are as many components as there are variables, two in this example. However, SEIFA uses only the First component (and only this First component is shown in the figure). While this component captures the most information possible by a single component, this First component captures only a proportion of the information contained in the variables. <back
 Print Page
Print Page
 Print All
Print All