Introduction
1 The ABS has produced an experimental socio-economic index for households from the 2016 Census of Population and Housing (Census), utilising the approach presented in Building on SEIFA: Finer levels of Socio-Economic Summary Measures by Phillip Wise and Courtney Williamson (cat. no. 1352.0.55.135).
2 A household is defined as one or more persons, at least one of whom is at least 15 years of age, usually resident in the same private dwelling. All occupants of a dwelling form a household. For Census purposes, the total number of households is equal to the total number of occupied private dwellings (Census of Population and Housing: Census Dictionary cat. no. 2901.0). These explanatory notes will refer to ‘household’ rather than dwelling, as the index is designed to represent advantage and disadvantage at household level.
3 The Australian Statistical Geography Standard (ASGS) was used in the development and analysis of the index. Information about the ASGS is presented in Australian Statistical Geography Standard (ASGS): Volume 1 - Main Structure and Greater Capital City Statistical Areas (cat. no. 1270.0.55.001).
What is the IHAD?
4 The Index of Household Advantage and Disadvantage (IHAD) is an experimental analytical index developed by the ABS. It provides a summary measure of relative socio-economic advantage and disadvantage for households, based on the characteristics of dwellings and the people living within them.
5 Socio-Economic Indexes for Areas (SEIFA) summarises different aspects of the socio-economic conditions of an area in which a person lives. The index values are assigned to areas, not to persons or households. Within any area there are likely to be households with different characteristics to the overall population of that area. For example, a relatively disadvantaged area is likely to contain a number of households that are relatively advantaged; likewise a relatively advantaged area is likely to contain a number of households that are relatively disadvantaged.
6 Using an area-based measure like SEIFA as a measure of household or individual level socio-economic advantage or disadvantage is likely to result in some households and individuals being misclassified. This is known as the ecological fallacy. Wise and Mathews (2011) investigated the extent of this issue as it relates to SEIFA. They proposed creating a household level index as an adjunct to SEIFA, to better illustrate the heterogeneity of advantage and disadvantage within an area.
7 The IHAD complements the area level SEIFA rankings by allowing the relationship between area level disadvantage and household level disadvantage to be explored. IHAD can also be cross-classified with other Census variables to provide valuable insights in its own right.
8 There are a range of conceptual and technical challenges in the construction of a household level index of socio-economic advantage and disadvantage. As an experimental index, users should note the limitations before drawing conclusions based on the IHAD results. See section Limitations and considerations when using the IHAD.
Advantage and disadvantage: The concepts
9 The concept of household level socio-economic disadvantage for the IHAD relates to the individual access to resources of people living within households and their ability to collectively share these resources in order to participate in society (Wise and Williamson, 2013).
10 In most households, members often pool their income and resources and share similar living characteristics. A household can still be advantaged overall as a unit even if it contains some less advantaged members. This support isn’t restricted to economic aspects; for example, children within households containing people with higher levels of education may be more advantaged in educational outcomes than children in households containing people with lower levels of education.
11 Since relative socio-economic advantage and disadvantage is a complex and multidimensional concept, it is difficult to condense into a single index. The limitations of the data collected in the Census also place restrictions on measuring this concept. The most important dimensions covered by SEIFA and the IHAD include occupation, income and education.
12 An important point to consider at all times is both what is measured by a socio-economic index, and what is not measured.
Limitations and considerations when using the IHAD
Measurement challenges
13 Previous research has noted challenges in the construction of individual level indexes due to the fact that the available indicators of advantage and disadvantage may not necessarily be equally relevant in identifying advantage or disadvantage for all persons in the population.
14 For example, Baker and Adhikari (2007) and Wise and Mathews (2011) found that it was not feasible to calculate accurate individual measures of advantage and disadvantage for persons aged under the age of 15 or over the age of 64, as factors associated with advantage and disadvantage for these age groups were not well captured by the available Census data.
15 An index value indicating a particular level of advantage or disadvantage may therefore not be equally as accurate in identifying underlying advantage or disadvantage across different age groups. For example, being employed in a highly skilled occupation or earning a high income would generally be indicative of being relatively advantaged. However, for retirees, their low income or lack of employment at the time of the Census is not necessarily reflective of their level of underlying disadvantage, as they may instead be supporting their lifestyle by drawing on the wealth they have accumulated over their lifetime.
16 As older persons are likely to live alone or with other persons with similar characteristics, many of the issues noted above are equally applicable to household level indexes such as the IHAD.
17 Accumulated wealth may be a more reliable indicator of advantage for older persons than income or occupation. However, as it is not able to be well reflected in the calculation of the IHAD, this may result in an overstatement in the level of disadvantage being experienced by older persons. Aside from wealth, there are a number of other potential aspects of advantage and disadvantage which the index does not represent well due to limited information available about them from the Census. Examples include:
- Health
- Access to services
- Social and community participation
18 If data were available on these topics, they may provide additional information about the level of advantage and disadvantage present within households that could result in households being assigned a different index value. See paragraph 32 for a list of variables that were considered but not included in the candidate variable list.
Persons temporarily away from home
19 The IHAD is calculated based on the characteristics of persons who are both usually resident in a household and enumerated in that household on Census Night. If all usual residents of a household aged 15 or more were away from home on Census Night, that dwelling would be out of scope of the IHAD (see section Scope).
20 Persons temporarily overseas on Census Night are out of scope of the Census, and thus Census data is not available for those persons. Persons staying elsewhere in Australia are in scope of the Census, but they are not able to be associated back to their dwelling of usual residence, and therefore their characteristics as measured in the Census are not able to be used in the derivation of the household level variables used in the index.
21 If one of more usual residents were away, but at least one person was at home on Census Night, then that dwelling remains in scope of the IHAD and an index value would be calculated for that household. However, the persons temporarily away from that dwelling would not have their characteristics contributing to the index value for that household; only those persons present will. This may result in a different level of advantage or disadvantage being calculated for that dwelling than would have been the case had all persons usually resident in that dwelling been at home on Census Night. Around 6% of in scope dwellings had one or more usual residents away from home on Census Night.
22 An example of this situation would be a one family couple household with two adults usually resident. One member of the couple is unemployed and was at home on Census Night, while the other person was travelling for work-related reasons. The person characteristics used in the calculation of the IHAD are based only on the characteristics of the (unemployed) person that was home on Census Night.
Household level index
23 The IHAD is constructed at the household level, based on the assumption that economic and other resources are generally shared within households, and therefore persons within households will share similar levels of socio-economic advantage and disadvantage. However, this may not always be the case, particularly for multi-family households, group households, and households containing lodgers or boarders. It is possible for a relatively advantaged person to be a resident in a relatively disadvantaged household or a relatively disadvantaged person to reside in a relatively advantaged household.
24 Quantiles are created based on assigning, as near as is practicable, equal numbers of households into each quantile (rather than equal numbers of persons). As larger households tend to have higher index values, more advantaged quantiles tend to contain larger numbers of persons.
Relationship with census variables
25 As the IHAD is constructed using Census variables, when undertaking analyses involving cross-tabulation of the IHAD with other Census variables, users should examine the variables contained within the index to aid in the interpretation of those results. Refer to section Choosing the variables for summaries of variables that were included in the final IHAD as well as those that were considered for inclusion.
Constructing the index
26 Broadly the steps undertaken to construct the IHAD are as follows.
- Initial variable list created
- Variables constructed
- Very highly correlated variables removed
- Initial PCA conducted
- Low loading variables removed
- PCA conducted on reduced list of variables
- Component/index scores standardised
- Sign of index reversed if necessary
- Households sorted for assignment to quantiles
27 The following section discusses these steps in more detail, with additional information on the scope, missing responses and imputation, and confidentiality.
Choosing the variables
28 Variables were included in the initial candidate variable list if they were deemed to be related to the definition of advantage and disadvantage that the IHAD is intending to capture. The main constraint to the initial variable list is that the variables can only be sourced from Census data.
29 The candidate variable list used in previous research (Wise and Williamson, 2013) was reviewed, as well as the candidate variables used for 2016 SEIFA. This was to ensure all aspects of advantage and disadvantage that could be reflected with the use of Census variables were included in the candidate variable list.
30 The types of variables considered for use in the household level index were:
- SEIFA variables that relate directly to households
- Person and family based SEIFA variables adapted to the household level
- New and representative household variables derived from Census data (household, and person or family based adapted to household level)
31 Family and person level variables have been derived at the household level. For example, for the candidate variable ‘households where the person with the highest educational attainment has a Bachelor Degree or above’, the highest qualification for all in scope persons in the household is considered and if one person has a Bachelor Degree or higher, the derived variable has a value of 1. If no people in the household have a Bachelor Degree or higher, the value is 0. For the candidate variable ‘households where all people aged 15 years and over are unemployed’ if all in scope people aged 15 years and over in the household have labour force status unemployed, the derived variable will have a value of 1, otherwise it will have a value of 0.
32 The cut-off values that are used to determine which dwellings are considered to have high or low income, mortgage repayments, and rent, align with those used for 2016 SEIFA. These were updated, based on the most recent Census, to reflect real-world changes. For household income, the cut-off values were set so that the high income variable captured the 5th income quintile and the low income variable captured the 1st quintile. Similarly, for the mortgage and rent variables, the high value cut-off captures the 5th quintile while the low value cut-off captures the 1st quintile.
33 The list of candidate variables is presented in the following tables. All of the variables are binary indicators as this aligns with previous ABS research into finer level socio-economic indexes. Variables are followed by either “adv” or “dis” to indicate whether they are an advantage or disadvantage for households.
List of household variables
| Variable mnemonic | Variable description |
|---|---|
| NOCAR | Households with no car (dis). |
| HIGHCAR | Households with three or more cars (adv). |
| FEWBED | Households with one or no bedrooms (dis). |
| HIGHBED | Households with four or more bedrooms (adv). |
| OVERCROWD | Households requiring one or more extra bedrooms (based on Canadian National Occupancy Standard) (dis). |
| SPAREBED | Households with one or more bedrooms spare (based on Canadian National Occupancy Standard) (adv). |
| OTHER_HHLD | Households with a structure classified as "other" (e.g. caravan, tent) (dis). |
| NONET | Households without internet connection (dis). |
| MULTI_FAMILY | Multi-family households (adv). |
| LOWRENT | Households where rent payments are less than $215 per week, excluding employer landlords (excludes $0) (dis). |
| HIGHRENT | Households where rent payments are more than $470 per week (adv). |
| PUBLIC_RENT | Households being rented from a state or territory housing authority, or a housing co-operative/community/church group (dis). |
| OWNED | Households owned outright (adv). |
| PURCHASED | Households being purchased (adv). |
| HIGHMORTGAGE | Households where mortgage repayments are greater than $2,800 per month (adv). |
| AREA_RVR | Households in remote/very remote area (dis). |
| AREA_MC | Households in major cities (adv). |
List of family variables
| Variable mnemonic | Description |
|---|---|
| ONEPARENT | Households with a one-parent family, with dependent children only (dis). |
| CHILDJOBLESS | Households with children aged under 15 years and parent(s) not employed (dis). |
List of person variables - education
| Variable mnemonic | Description |
|---|---|
| NOYEAR11orhigher | Households where the person with the highest educational attainment left school at year 10 or below, including those who did not go to school and with Certificate level I or II (excludes those currently studying secondary education) (dis). |
| YEAR11 | Households where the person with the highest educational attainment left school at year 11 (excludes those currently studying secondary education) (dis). |
| CERTIFICATE | Households where the person with the highest educational attainment has a Certificate III or IV (adv). |
| DIPLOMA | Households where the person with the highest educational attainment has an Advanced Diploma or Diploma (adv). |
| DEGREE | Households where the person with the highest educational attainment has a Bachelor Degree or above (adv). |
| DEGREE_DEPENDENT* | Households with at least one dependent child and the person with the highest educational attainment has a Bachelor Degree or above (adv). |
| NOYEAR12_DEPENDENT* | Households with at least one dependent child and the person with the highest educational attainment left school at year 11 or below, including those who did not go to school and with Certificate level I or II (excludes those currently studying secondary education) (dis). |
* Combining education level with dependent children represents the concept of household level advantage/disadvantage to children from having or not having educated parents. Dependent children are derived using CDCF (Counts the number of dependent children in the family). A dependent child is a person who is either a child under 15 years of age, or a dependent student aged 15-24 years.
List of person variables - occupation
| Variable mnemonic | Description |
|---|---|
| INC_LOW | Households with low annual equivalised income (between $1 and $25,999) (dis). |
| INC_HIGH | Households with high annual equivalised income (greater than $78,000) (adv). |
| ALL_UNEMPLOYED | Households where all people aged 15 years and over are unemployed (dis). |
| HIGH_SKILL | Households where the highest skilled employed adult works in a skill level 1 occupation (adv). |
| SKILL_LVL_2 | Households where the highest skilled employed adult works in a skill level 2 occupation (adv). |
| SKILL_LVL_4 | Households where the highest skilled employed adult works in a skill level 4 occupation (dis). |
| LOW_SKILL | Households where the highest skilled employed adult works in a skill level 5 occupation (dis). |
| ALL_SHORT_DISTANCE | Households where all people aged 15 years and over who are employed, travel 0 to less than 2.5 km to work (adv). |
| ALL_LONG_DISTANCE | Households where all people aged 15 years and over who are employed, travel 50 to less than 250 km to work (dis). |
| ALL_VLONG_DISTANCE | Households where all people aged 15 years and over who are employed, travel 250 or more km to work (dis). |
List of person variables - miscellaneous
| Variable mnemonic | Description |
|---|---|
| SEP_DIVORCED | Households with one or more people aged 15 years and over separated or divorced (dis). |
| ENGPOOR | Households with one or more people aged 15 years and over who do not speak English well (dis). |
| ROM | Households with one or more people aged 15 years and over who arrived in Australia in the last 10 years (dis). |
| UNENGAGED_YOUTH | Households with one or more people aged between 15 and 24 years who are not working or studying (dis). |
| DISABILITY_UNDER70 | Households with one or more people aged under 70 years who need assistance with core activities (dis). |
| DISABILITY_HH_PROP | Households where more than 50% of people need assistance with core activities (dis). |
| CARER | Households with one or more people aged 15 years and over who provide unpaid assistance to a person with a disability (dis). |
| VOLUNTEER | Households with one or more people aged 15 years and over who does voluntary work for an organisation or group (adv). |
| RETIRED_NOT_OWNED | Households with a person aged 65 years and over who does not own the home, or occupy it under a life tenure scheme (dis). |
34 In most cases, highly correlated variables were removed from the initial candidate list. This was done to prevent instability in the variable weights and over-representation of any specific socio-economic characteristic. When two variables had a correlation coefficient of size greater than 0.8 in absolute value, one of them was generally removed. However, if they were deemed to be measuring different socio-economic characteristics (e.g. education and occupation), both were retained.
35 The following table presents the variables excluded from the initial candidate list; this includes those that were highly correlated, additional variables considered and discarded, and variables discussed with stakeholders that are not currently available from the Census. Please note that additional variables not included here could also be considered as potential household advantage and disadvantage variables.
Variables discussed in consultation with stakeholders but not included in the candidate variable list
| Variable description | Reason for exclusion |
|---|---|
| Households with only one person aged 15 years and over (lone person household). | Neither a clear advantage or disadvantage. Can be either a personal choice or stage of life and also varies across age groups and sex. Likely to be correlated with other variables. |
| Households with only people aged 0-24 years. | Age is not a clear advantage or disadvantage. Other characteristics such as low income, long term health conditions and marital status become more prevalent as age increases and are included in the candidate variable list where possible. For analysis that compares age groups, it is sensible to not include age specific variables in the candidate list. |
| Households with only people aged 25-64 years. | |
| Households with only people aged 65 years and over. | |
| Households with one or more people aged 15 years and over who are unemployed (dis). | Highly correlated with ALL_UNEMPLOYED which highlights disadvantaged households better. |
| Households with one or more people aged 70 years and over who need assistance with core activities (dis). | Highly correlated with DISABILITY_HH_PROP (0.83) and not as representative of the total population. |
| Households where all people aged 15 years and over have no educational attainment (dis). | Small prevalence and highly correlated with NOYEAR11orhigher. |
| Households where the highest skilled employed adult works in a skill level 3 occupation. | Neither advantage or disadvantage, better reflected by HIGH_SKILL and LOW_SKILL. |
| Households where the person with the highest educational attainment left school at year 11 or below, including those who did not go to school and with Certificate level I or II (excludes those currently studying secondary education) (dis). | Narrowed the concept of household educational disadvantage to those who left school at year 10 or below (NOYEAR11orhigher). |
| Households with one or more people aged 15 years and over attending university (adv). | Low priority for stakeholders; this variable may reflect future advantage rather than current circumstances. |
| Households with one or more employed adults classified as Low Skill Clerical and Administrative Workers (dis). | Variables created for consistency with SEIFA. Determined that the SKILL_LVL_# variables better reflect occupation-related advantage and disadvantage at the household level. |
| Households with one or more employed people classified as Machinery Operators and Drivers (dis). | |
| Households with one or more employed people classified as Labourers (dis). | |
| Households with one or more employed people classified as Managers (adv). | |
| Households with one or more employed people classified as Professionals (adv). | |
| Households with one or more employed people classified as Low Skill Sales (dis). | |
| Households with one or more employed people classified as Low Skill Community and Personal Service Workers (dis). | |
| Median house price at SA1 level. | Likely to introduce some of the issues with SEIFA at the area level - low value houses in an area with a comparatively high median house price. |
| Household main source of income. | Not available from 2016 Census; may be available in the future. |
| Measure of household wealth (broader than home ownership). | Not available from 2016 Census; might be available from alternate data sources in the future. |
| Proportion of income spent on rent/mortgage. | Census income collected in ranges and may not adequately account for rent assistance; might be available from other data sources in future. |
| Hours worked. | Unclear whether the number of hours worked is an advantage or disadvantage. Ideally we would want to include whether households include people who wanted to work more hours. |
| Employees versus owner/managers. | Unclear whether the number of hours worked is an advantage or disadvantage. |
| Dependents 15-24 who are employed and all parents are unemployed. | This represents a very small population approx. 22,000 households (0.3%). |
| Household mobility – 1 year and 5 year. | Unclear whether this is an advantage or disadvantage. Moving is a stress point but this might not equate to longer term advantage or disadvantage. |
| Long-term health conditions. | Not available from 2016 Census; may be available in the future. |
Scope
36 The scope of the IHAD is private dwellings that were occupied on Census Night. Unoccupied private dwellings, non-private dwellings, and non-classifiable dwellings (e.g. dwellings that did not return a Census form and visitor only households) were all excluded. This accounted for approximately 1.6 million dwellings or 16.5% of all dwellings. Approximately 1.0 million (10.5%) were unoccupied private dwellings; 0.6 million (5.8%) were non-classifiable dwellings. Note that residents in boarding houses and hostels are not included as these are classified as non-private dwellings.
| Census (all - in scope) | Excluded from index | % |
|---|---|---|
| 9.92 - 8.29 million dwellings | 1.64 million dwellings | 16.5 |
Exclusions
37 Rules for the minimum number of persons and dwellings for an area to receive an index score has been a feature of SEIFA since its inception following the 1986 Census. In the Statistical Areas Level 1 (SA1) data cube available in the Data downloads section, IHAD quartile percentages will not be provided for SA1s that do not have a SEIFA score.
Missing responses
38 Data quality considerations for construction of an index at household level centre on the level of non-response to Census questions. Overall non-response was relatively low (around 3-4%) and fairly consistent across candidate variables, with the exception of equivalised total household income (HIED) and level of highest educational attainment (HEAP) (around 10-12%). Please refer to the Census of Population and Housing: Census Dictionary (cat. no. 2901.0) for details about these variables.
39 Due to partial non-response from some Census respondents, some households could not be included in the IHAD construction without some action to account for missing values within candidate variables. For example, for the candidate variable ‘Households where all people aged 15 years and over are unemployed (dis)’, if someone within the household does not indicate their labour force status, it may not be possible to assign a value for this candidate variable.
40 Two actions to deal with missing data have been applied:
- removal of households with high numbers of non-response
- imputation of missing values
Removal of households with high numbers of non-response
41 Households with 10 or more missing candidate variable responses have been removed. This number was chosen because it tended to correspond to dwellings where most person based variables were coded as 'not stated' (Wise and Williamson, 2013). Approximately 0.4% of in scope households (41,750) were removed; the proportion of households with 3 or fewer missing candidate variable responses was approximately 96%.
Imputation of missing values
42 Wise and Williamson (2013) noted that if ‘not stated’ responses are grouped with records that do not have a particular disadvantaging characteristic, then there is an implicit advantage being assigned to those individuals. They recommended that imputation should be performed where appropriate.
43 Missing values for household, family, and person level Census variables that were required have been imputed. The method used randomly assigned missing responses for a given variable to one of the allowed responses, based on the frequency proportions for the variable at the national level. As a result, the distribution of the imputed responses for most of the variables being treated aligned within reasonable bounds with the original distribution of non-missing responses.
44 This was also true for HIED (equivalised total household income) at the national level. However, within household composition categories the distribution of imputed values was more variable. By state, the rate of non-response for HIED was between 10-12%; when looking at different household compositions it ranged from 11-21%, with group and multiple family households having the higher values within that range. Similar results were observed for HEAP (level of highest educational attainment).
45 Due to this variability, hot-deck imputation was applied to HIED and HEAP. This involved assigning a value for the missing HIED/HEAP variable from a donor that matched the recipient’s values for a selection of other Census variables. For HIED the selection of variables were: household composition, state or territory, SA2, and number of adults and employed people in the household; for HEAP the selection of variables were: age in 10 year groups, state or territory, SA2, level of non-school qualification, highest year of school completed, total personal weekly income and labour force status. The distribution of the imputed responses for each of the variables improved from the initial imputation approach and was deemed to be sufficient for the purpose of constructing the IHAD.
The method
46 Principal component analysis (PCA) has been used since the first release of SEIFA to summarise Census variables related to socio-economic advantage and disadvantage. The same methodology is used to create the IHAD. The aim of PCA is to reduce a large number of correlated variables into a smaller set of transformed variables, called "principal components". Each component is a weighted linear combination of the original. It is possible to extract as many components as there are variables. If the original variables are highly correlated, much of the variation can be summarised by a single principal component.
47 The first principal component is the weighted linear combination of variables that captures the maximum amount of variation present in the original dataset. This is calculated using the correlations between the variables. In general, variables that are strongly correlated with many others in the list will receive high weights. The first principal component is used to create the IHAD index.
48 The PCA used the binary candidate variables and the correlation matrix of these variables to give an indication of how significantly each variable contributes to the measurement of the unobserved latent variable of interest, namely socio-economic advantage and disadvantage. Each variable receives a loading that indicates the correlation of that variable with the index. A positive loading indicates an advantaging variable where as a negative loading indicates a disadvantaging variable. The variables with the highest loadings are the ones that have the highest correlation with the index value.
49 Polychoric correlations were used instead of the standard Pearson correlations for the correlation matrix; this is appropriate for binary variables to ensure the correlation coefficients used in the PCA are unbiased. Using polychoric correlations is considered to be more accurate when running a PCA on discrete data such as the binary variables used in the IHAD.
50 The candidate variables listed in paragraph 30 were used in the PCA for the IHAD, and removed if their loading was less than or equal to 0.3 on the grounds that they were not particularly strong indicators of advantage or disadvantage. This process was performed iteratively, until all of the variables had a loading above 0.3. This is the same procedure used to create the SEIFA. The final variables and their loadings following this process are presented in paragraph 51.
51 The first principal component scores were derived by taking the product of each standardised variable with its respective weight, then taking the sum. For convenience and consistency with the approach taken for SEIFA, these raw component scores were then standardised to a mean of 1,000 and a standard deviation of 100 to produce the index.
52 The sign of the PCA weights is arbitrary, but intuitively we want more disadvantaged households to have lower scores, for example NOCAR is a disadvantage variable and so should have a negative weight. The weights were multiplied by -1 to give advantage indicators positive weights and loadings, and disadvantage indicators negative weights and loadings. Accordingly, high index scores indicate relative advantage, and low index scores indicate relative disadvantage.
Results
53 The variables that are included in the index can be found below. Note that the loadings are closely related to the variable weights used in the construction of the index.
54 The IHAD explains 43.2% of the total variance of the variables in the final variable list.
Final PCA variables and their loadings
| Variable mnemonic | Description | Loading |
|---|---|---|
| PUBLIC_RENT | Households being rented from a state or territory housing authority, or a housing co-operative/community/church group (disadvantage). | -0.82 |
| LOWRENT | Households where rent payments are less than $215 per week, excluding employer landlords (excludes $0) (disadvantage). | -0.81 |
| INC_LOW | Households with low annual equivalised income (between $1 and $25,999) (disadvantage). | -0.71 |
| NOYEAR11orhigher | Households where the person with the highest educational attainment left school at year 10 or below, including those who did not go to school and with Certificate level I or II (excludes those currently studying secondary education) (disadvantage). | -0.70 |
| NONET | Households without internet connection (disadvantage). | -0.66 |
| NOCAR | Households with no car (disadvantage). | -0.63 |
| RETIRED_NOT_OWNED | Households with a person aged 65 years and over who does not own the home, or occupy it under a life tenure scheme (disadvantage). | -0.58 |
| DISABILITY_HH_PROP | Households where more than 50% of people need assistance with core activities (disadvantage). | -0.55 |
| NOYEAR12_DEPENDENT | Households with at least one dependent child and the person with the highest educational attainment left school at year 11 or below, including those who did not go to school and with Certificate level I or II (excludes those currently studying secondary education) (disadvantage). | -0.51 |
| FEWBED | Households with one or no bedrooms (disadvantage). | -0.46 |
| ALL_UNEMPLOYED | Households where all people aged 15 years and over are unemployed (disadvantage). | -0.42 |
| YEAR11 | Households where the person with the highest educational attainment left school at year 11 (excludes those currently studying secondary education) (disadvantage). | -0.36 |
| CHILDJOBLESS | Households with children aged under 15 years and parent(s) not employed (disadvantage). | -0.36 |
| HIGHCAR | Households with three or more cars (advantage). | 0.44 |
| HIGHBED | Households with four or more bedrooms (advantage). | 0.50 |
| INC_HIGH | Households with high annual equivalised income (greater than $78,000) (advantage). | 0.66 |
| PURCHASED | Households being purchased (advantage). | 0.73 |
| DEGREE | Households where the person with the highest educational attainment has a Bachelor Degree or above (advantage). | 0.75 |
| HIGHMORTGAGE | Households where mortgage repayments are greater than $2,800 per month (advantage). | 0.77 |
| HIGH_SKILL | Households where the highest skilled employed adult works in a skill level 1 occupation (advantage). | 0.77 |
| DEGREE_DEPENDENT | Households with at least one dependent child and the person with the highest educational attainment has a Bachelor Degree or above (advantage). | 0.80 |
55 In line with standard ABS procedures to minimise the risk of identifying individuals, a technique has been applied to randomly adjust cell values of the output tables. These adjustments may cause the sum of rows or columns to differ by small amounts from table totals.
Checking the index makes sense
56 Once the index was calculated, it was checked to ensure that it measures the desired concept and that the results make intuitive sense. This is vital to establish the validity of the index.
57 A particular focus of validation centred on confronting the IHAD against the 2016 SEIFA Index of Relative Socio-Economic Advantage and Disadvantage to ensure the expected level of consistency was present.
58 In particular, two scenarios were investigated at the SA1 level:
- SA1s that are most advantaged according to SEIFA (quartile 4), but a majority of households in that SA1 were disadvantaged according to IHAD (quartiles 1 and 2).
- SA1s that are most disadvantaged according to SEIFA (quartile 1), but a majority of households in that SA1 were advantaged according to IHAD (quartiles 3 and 4).
| Scenario | Proportion of SA1s |
|---|---|
| 1. SA1s in SEIFA quartile 4, where the proportion of households in the lowest two IHAD quartiles > 50% | 123/55028 = 0.2% |
| 2. SA1s in SEIFA quartile 1, where the proportion of households in the highest two IHAD quartiles > 50% | 90/55028 = 0.2% |
59 Some patterns emerged from this investigation for particular small groups within the population; consideration should be given to the appropriate use of the IHAD for these groups.
Group 1 – Lone person households with people aged 65+ years:
- SA1s with a high proportion of lone person households with people aged 65+. Employment and occupation variables likely do not accurately signify underlying levels of advantage or disadvantage for this group, and wealth is not well represented by available candidate variables.
Group 2 – Lone person households and student areas:
- SA1s with a high proportion of lone person households and university students. Variables that in general represent disadvantage in the broader population may not reflect disadvantage for this group. For example in inner city areas not owning a car may not be a sign of disadvantage. In addition, attending university was not included in the index as a candidate variable to signify advantage.
Group 3 – Households with large homes and not high income:
- SA1s with a high proportion of dwellings with 4 or more bedrooms and a high proportion of family households with low or moderate household income. Variables that represent advantage, for example owning a home, may not reflect advantage for this group. Housing stress (proportion of income devoted to mortgage/rent) is not included in the SEIFA or IHAD.
Interpreting the IHAD
60 The 2016 Index of Household Advantage and Disadvantage summarises information about the economic and social conditions of people within households, including both relative advantage and disadvantage measures.

61 A low score indicates relatively greater disadvantage and a lack of advantage in general. A high score indicates a relative lack of disadvantage and greater advantage in general.
62 As a measure of socio-economic conditions, the index is best interpreted as an ordinal measure. It can be used to understand the distribution of socio-economic conditions across different households. Index scores are on an arbitrary scale. The scores do not represent some quantity of advantage or disadvantage. For example, we cannot infer that a household with an index score of 1000 is twice as advantaged as a household with an index score of 500.
63 For analytical convenience, households are grouped together with similarly advantaged or disadvantaged households into equally sized groups or quantiles.
64 IHAD data has been presented as quartiles (four groups). Households are ordered from the lowest to the highest index value, with the lowest 25% of households assigned to quartile 1, the next lowest 25% of households to quartile 2 and so on, up to the highest 25% of households which are given a quartile number of 4. This means that households are divided into four equal sized groups, with quartile 1 representing the most disadvantage households and quartile 4 representing the most advantaged households. In practice these groups won’t each contain exactly 25% of households as it depends on the distribution of the IHAD scores. Note that the groups will have an approximately equal number of households, not an approximately equal number of persons.
65 The following graph presents the distribution of IHAD scores; the table presents maximum and minimum scores of each IHAD quartile. These show that there is sufficient variation in the IHAD scores to allow for the formation of these groups.
66 Some households will not have any indicators of advantage or disadvantage (i.e. their values for the final binary candidate variables are all 0). They will still receive an IHAD score reflecting the middle of the IHAD score distribution, which places them in quartile 2.
Distribution of IHAD scores
Image
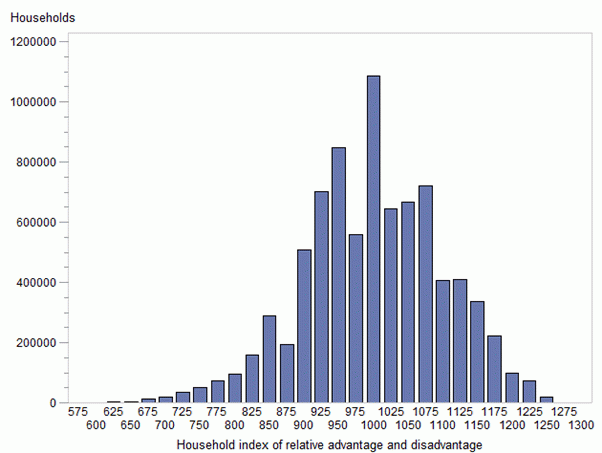
Description
Frequency distribution of ranked household index groups
| Number of households* | Household index score | |||
|---|---|---|---|---|
| Household index group | Frequency | Percentage | Minimum | Maximum |
| 1 | 2,060,960 | 25.0 | 628 | 931 |
| 2 | 2,114,803 | 25.7 | 931 | 1000 |
| 3 | 1,999,396 | 24.3 | 1000 | 1070 |
| 4 | 2,069,169 | 25.1 | 1070 | 1248 |
* The total number of in-scope households assigned an IHAD score is 8,244,328
References
Show all
Australian Bureau of Statistics (2013) ANZSCO – Australian and New Zealand Standard Classification of Occupations, Version 1.2, cat. no. 1220.0, ABS, Canberra.
Australian Bureau of Statistics (2016a) Australian Statistical Geography Standard (ASGS): Volume 1 - Main Structure and Greater Capital City Statistical Areas, cat. no. 1270.0.55.001, ABS, Canberra.
Australian Bureau of Statistics (2016b) Census of Population and Housing: Census Dictionary, cat. no. 2901.0, ABS, Canberra.
Australian Bureau of Statistics (2018) Census of Population and Housing: Socio-Economic Indexes for Areas (SEIFA), Australia, 2016, cat. no. 2033.0.55.001, ABS, Canberra.
Wise, P. and Mathews, R. (2011) “Socio-Economic Indexes For Areas: Getting a Handle on Individual Diversity Within Areas”, Methodology Research Papers, cat. no. 1351.0.55.036, Australian Bureau of Statistics, Canberra.
Wise, P. and Williamson, C. (2013) “Building on SEIFA: Finer Levels of Socio-Economic Summary Measures”, Methodology Research Papers, cat. no. 1352.0.55.135, Australian Bureau of Statistics, Canberra.