INTRODUCTION
The Australian Census Longitudinal Dataset (ACLD) uses data from the Census of Population and Housing to build a rich longitudinal picture of Australian society. The ACLD can uncover new insights into the dynamics and transitions that drive social and economic change over time, and how these vary for diverse population groups and geographies. Three waves of data have contributed to the ACLD so far, from the 2006, 2011 and 2016 Censuses.
There are two ACLD panels, representing a 5% sample of records from the 2006 Census and the 2011 Census, respectively. The 2006 Panel comprises of records from the original 2006 ACLD sample linked to records from the 2011 Census and the 2016 Census. The 2011 Panel is linked to records from the 2016 Census.
As new panels and information from subsequent Censuses are added to the ACLD, its value as a resource for longitudinal studies of the Australian population will continue increasing.
This paper describes the background and rationale for the ACLD, the data linkage methodology used for producing the 2006 and 2011 ACLD panels and an assessment of its quality.
1.1 OVERVIEW
Development
In 2005, the ABS embarked on a project to enhance the value of Census data by bringing it together with other datasets, both ABS and non-ABS, to leverage more information from the combination of datasets than would be available from the individual datasets separately. The ACLD was proposed as an enduring longitudinal dataset constructed through the linking of records from successive Censuses.
As part of the development phase, a quality study was undertaken in which data from the 2005 Census Dress rehearsal were linked to data from the 2006 Census. This quality study concluded that the linkage methodology was feasible and that the expected quality of the linked data file would be sufficient for longitudinal analysis. For more information see, Assessing the Likely Quality of the Statistical Longitudinal Census Dataset (cat. no. 1351.0.55.026).
In 2013 the ABS released the first ACLD product, a 5% sample of the 2006 Census linked to the 2011 Census (the 2006 ACLD Panel). In preparation for adding 2016 Census data to the ACLD, a new panel of 2011 Census records was selected as a representative sample of the 2011 Census population. The 2011 Panel was designed to include:
- most of the 2011 Census records that were linked in the 2006 Panel;
- new records to account for missed links in the 2006 Panel; and
- new records to represent new births and migrants since the 2006 Census.
The 2011 Panel size was increased slightly to 5.7%, to achieve a linked sample size of no greater than 5% of the population after allowing for missed links and people in the 2011 sample not being in scope of the 2016 Census due to death or overseas migration (note that the linked sample size for the 2006 Panel linked to the 2011 Census was only 4.2%.) The 2011 ACLD Panel was released in 2018, consisting of the 2011 Panel sample of records from the 2011 Census linked to the 2016 Census.
In the March 2019 release, the 2006 Panel has been re-linked to the 2011 Census to take advantage of improved linking methodology since the initial release, and has then been linked to records from the 2016 Census.
Linking the ACLD
Data linkage is typically undertaken using a combination of deterministic and probabilistic methods:
- Deterministic linkage involves assigning record pairs across two datasets that match exactly or closely on common variables. This type of linkage is most applicable where the records from different sources consistently report sufficient information and can be an efficient process for conducting linkage
- Probabilistic linkage is based on the level of overall agreement on a set of variables common to the two datasets. This approach allows links to be assigned in spite of missing or inconsistent information, providing there is enough agreement on other variables.
For many individuals the linkage process will have accurately matched their corresponding records between Censuses. In some cases, the link will represent different people who share a number of characteristics in common. Some inaccuracy in the linkage will not generally affect statistical conclusions drawn from the linked data, although care should be taken in the interpretation of results. For more information see
Section 2 - Data Linking Methodology.
1.2 MULTI-PANEL SAMPLE DESIGN
Without sample maintenance, the ACLD would decline in its ability to accurately reflect the Australian population over time due to:
- people newly in scope of the ACLD (i.e. children born and immigrants arrived in Australia since the previous Census) not being represented in the sample;
- people selected in the ACLD sample no longer being in scope due to death or overseas migration; and
- missing and/or incorrect links (linkage bias).
Linkage bias in longitudinal datasets is unique to those created via data integration, as traditional longitudinal studies employ strategies to ensure they collect information about the same individual over time. In a linked longitudinal dataset, data integration is necessary due to a lack of a common identifier to identify a person's responses over time. Linkage bias occurs where certain populations are more difficult to link than others (e.g. Aboriginal and Torres Strait Islander people, young males), so links are more likely to not be identified for members of these groups and, if they are found, have a higher chance of being inaccurate. If left untreated, the representation of population groups suffering from linkage bias would worsen as each new Census is linked to the ACLD.
The ACLD sample is maintained through application of the Multi-Panel framework, developed by Chipperfield, Brown & Watson (2017). This framework provides an approach for selecting records in the ACLD to create panels which maintain the longitudinal and cross-sectional representativeness of the dataset over time, while minimising the impact of accumulated linkage bias on longitudinal analysis.
The Multi-Panel approach designs multiple overlapping panels, with each panel representing a single Census population (2006, 2011, 2016, etc.), which is then linked to subsequent Censuses. The sample selection strategy for each panel is designed to maintain a linked sample size of 5%, maximise sample overlap between the panels, and introduce new records to the dataset in each panel to account for new births, migrants and missed links in previous panels. This allows flexibility for users, who can draw on the most appropriate panel for their research question.
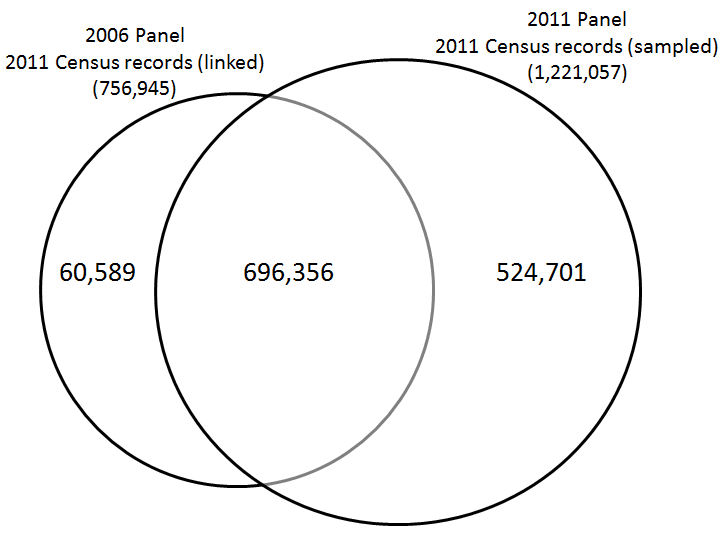
The sample overlap between the 2006 and 2011 ACLD Panels is illustrated below:
FIGURE 1 - SAMPLE OVERLAP BETWEEN THE 2006 AND 2011 ACLD PANELS
1.3 ACCESS TO THE ACLD
The ACLD is accessible online through ABS TableBuilder and DataLab. Through ABS TableBuilder clients can build, customise, save and export their own tables and graphs. In this product, confidentiality methods are applied to the data prior to output to ensure that information that is likely to enable identification of an individual or household will not be released. The DataLab is an interactive data analysis solution available for high end users to run advanced multivariate statistical analyses, for example, multiple regressions and structural equation modelling. The DataLab environment contains up to date versions of SPSS, Stata, SAS and R analytical languages. Controls in the DataLab have been put in place to protect the identification of individuals and organisations. These controls include environmental protections, data de-identification and confidentialisation, access safe guards and output clearance. All output from DataLab sessions is cleared by an ABS officer before it is released.
For more information, or to access the ACLD, see Microdata: Australian Census Longitudinal Dataset, ACLD (cat. no. 2080.0).
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All