TECHNICAL NOTE 1: DATA QUALITY
DATA QUALITY
When interpreting the results of a survey it is important to take into account factors that may affect the reliability of estimates. Such factors can be classified as either sampling error or non-sampling error.
SAMPLING ERROR
Estimates in these data cubes are based on information collected for a sample of registered motor vehicles, rather than a full enumeration, and are therefore subject to sampling error. They may differ from the data that would have been produced if the information had been obtained for all registered motor vehicles. Examples of the sampling error for this publication are included below.
The sampling error associated with any estimate can be calculated from the sample results. One measure of sampling error is given by the standard error, which indicates the extent to which an estimate might have varied by chance because only a sample of vehicles was included. There are about two chances in three that a sample estimate will differ by less than one standard error from the data that would have been obtained if all vehicles had been included, and about 19 chances in 20 that the difference will be less than two standard errors.
Another measure of sampling variability is the relative standard error (RSE) which is obtained by expressing the standard error as a percentage of the estimate to which it refers. The RSE is a useful measure in that it provides an immediate indication of the percentage error likely to have occurred due to sampling. In this publication, estimates that have an estimated relative standard error between 10% and 25% are annotated with the symbol '^' . These estimates should be used with caution as they are subject to sampling variability too high for some purposes. Estimates with an RSE between 25% and 50% are annotated with the symbol '*', indicating that the estimate should be used with caution as it is subject to sampling variability too high for most practical purposes. Estimates with an RSE greater than 50% are annotated with the symbol '**' indicating that the sampling variability causes the estimates to be considered too unreliable for general use.
As an example of the use of an RSE, the 2002 estimate for kilometres travelled by all passenger vehicles registered in Australia is 144,676 million kilometres The RSE for this estimate is 2%. Therefore, the standard error for the 2002 kilometres travelled by passenger vehicles estimate is 2,894 million kilometres. There are about two chances in three that the figure obtained if all vehicles had been included, would have been in the range 141,782 million kilometres to 147,570 million kilometres. There are about 19 chances in 20 that the figure would have been in the range 138,888 million kilometres to 150,464 million kilometres.
It is important to note that estimates at more detailed levels than the above are subject to higher RSEs and therefore are less reliable.
The SMVU is not designed to minimise the standard errors of the movements between reference periods. Care should be taken in drawing inferences from changes in data over time. The RSE for the movement can be calculated using:
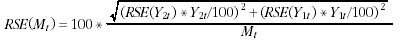
where
Y1t is an estimate of total of the variable of interest, obtained from the 1st time point
Y2t is an estimate of total of the same variable of interest, obtained from the 2nd time point.
Mt is an estimate of movement of the total of the variable of interest from the 1st time
point to the 2nd time point ie Mt = Y2t - Y1t
Some of the movements from the SMVU have an RSE of greater than 25%. This indicates that the change in the estimate from one period to the next is subject to sampling variability too high or too unreliable for practical use. It cannot be said with 95% (19 chances in 20) confidence that the movements are significantly different from zero.
NON-SAMPLING ERROR
Non-sampling error covers the range of errors that are not caused by sampling and can occur in any statistical collection whether it is based on full enumeration or a sample. For example, non-sampling error can occur because of non-response to the statistical collection, errors in reporting by providers, definition or classification difficulties, errors in transcribing and processing data and under-coverage of the frame from which the sample was selected. If these errors are systematic (not random) then the survey results will be distorted in one direction and therefore will be unrepresentative of the target population. Systematic errors are called bias.
Two steps undertaken to help minimise non-sampling error are pre-advice and the reduction in the reporting of rounded data. The pre-advice methodology involves vehicle owners receiving early advice about their inclusion in the survey. This encourages a higher degree of record keeping. In addition, the reporting of odometer readings taken at the start and end of the survey periods (approximately three months apart) provide reliable estimates of total distance travelled without a recall bias.
The second step is the reduction in the reporting of rounded data for total distance travelled. Such rounding could cause significant errors, especially with the prevalence of certain distances which could be seen as arbitrary guesses on the part of the provider. Where rounding is identified, providers are contacted and the estimate of their total distance travelled is queried. Distances considered to be rounded are every 1,000 km in the range 1,000 km up to 10,000 km and every 5,000 km for distances over 10,000 km.
Response and non-response
An important factor that affects non-sampling error is the response rate achieved. The ABS makes all reasonable efforts to maximise response rates. Where appropriate, mail reminders and telephone follow-up are used to attempt to contact non-responding vehicle owners.
A large non-response increases the potential for non-response bias, which occurs if the usage patterns of the non-responding vehicles differ significantly from those of the responding vehicles. For the SMVU, it is assumed that the characteristics of non-responding vehicles including the proportion of deregistered, out of scope and nil use vehicles are the same as for responding vehicles.
RESPONSE AND NON-RESPONSE, By category
 | | Percentage of selections | Percentage of selections | Percentage of selections |
| | 1998 | 1999 | 2002 |
|
| Response received | | | |
| Registered vehicle | 71 | 73 | 76 |
| Unregistered vehicle(a) | 6 | 6 | 5 |
| | | | |
| Non-response | | | |
| Untraceable - mailing address unknown | 11 | 10 | 7 |
| Other(b) | 12 | 11 | 12 |
| | | | |
| Total selections | 100 | 100 | 100 |
(a) Includes deregistration, out of scope and duplicates.
(b) Includes responses that were unusable because of unresolved queries or where the vehicle was sold during the reference quarter and the reported data covered less than 14 days; and non-response where no listing could be found to enable contact by telephone, owner contacted by telephone but response still not secured and refusals.
Imputation
The need for imputation of unfilled items on the returned questionnaires, as for previous surveys, remained quite high. Imputation is the process whereby a value is generated for missing data items by averaging the responses for similar vehicles which were operating for the reference period. Of the questionnaires returned for 1998, 1999 and 2002 there were 12%, 14% and 16% respectively of those reporting some vehicle use that needed imputation of one or more items apart from the average rate of fuel consumption. The imputations for average rate of fuel consumption for 1998, 1999 and 2002 were 24%, 26% and 26% respectively.
Adjustments
The SMVU measures the use of all vehicles registered during the reference year. Because selections are taken from vehicles registered some time before the beginning of each collection period, adjustments and additional selections from new motor vehicle registrations are made to account for the change in size of the registered motor vehicle fleet since the population frame was created. This involved two categories:
- re-registrations - older vehicles that are returning to the registered vehicle fleet after a period of deregistration, and
- new motor vehicles - vehicles which have not been previously registered.
These activities occur continuously and the adjustments are made to account for the registrations that are estimated to have been added to the registered vehicle fleet between the population frame date and the reference period.
Refer to Technical Note 2: Methodological Review for details of changes made as a result of the review.
Users should contact the ABS if they have any queries on the quality and reliability of estimates for particular purposes.
 Print Page
Print Page
 Print All
Print All