TECHNICAL NOTE RELIABILITY OF ESTIMATES
ESTIMATES
1 Estimates provided in this report are based on information obtained from samples of households and persons. Estimates are subject to sampling and non-sampling error.
Non-sampling error
2 Non-sampling error may arise as a result of error in the reporting, recording or processing of data and can occur even if there is complete enumeration of the population. Non-sampling error can be introduced through inadequacies in the questionnaire, non-response, inaccurate reporting by respondents, error in the application of survey procedures, incorrect recording of answers and errors in data entry and processing.
3 It is not possible to measure the size of the non-sampling error. The extent of this error could vary considerably from survey to survey and from question to question. Every effort is made in the design of the survey and development of survey procedures to minimise the effect of this type of error.
Sampling error
4 Sampling error is the difference between the published estimates, derived from a sample of persons, and the value that would have been produced if all persons in scope of the survey had been included.
ESTIMATES OF SAMPLING ERROR
5 One measure of the variability of estimates which occurs as a result of surveying only a sample of the population is the standard error (SE).
6 There are about two chances in three that a sample estimate will differ by less than one SE from the figure that would have been obtained if all households had been included in the survey and about 19 chances in 20 that the difference will be less than two SEs.
7 Tables of standard errors of household and person estimates are provided for 1998 to 2003 below. Standard estimates are provided to enable readers to determine the SE for an estimate from the size of that estimate. The SE is derived from a mathematical model, referred to as the 'SE model', which is created using data from the four different survey vehicles. It should be noted that the SE model only gives an approximate value for the SE for any particular estimate, since there is some minor variation between SEs for different estimates of the same size.
STANDARD ERRORS OF HOUSEHOLD ESTIMATES - 1998-2002 |
|  |
| 1998 | 1999 | 2000 | 2001 | 2002 | |
| Size of estimate | no. | no. | no. | no. | no. | |
| |
| 2,000 | .. | .. | .. | 960 | 1 130 | |
| 5,000 | 2 100 | 2 100 | 2 100 | 1 680 | 1 930 | |
| 10,000 | 2 900 | 2 900 | 2 900 | 2 500 | 2 800 | |
| 20,000 | 3 900 | 3 900 | 3 900 | 3 550 | 4 000 | |
| 50,000 | 5 600 | 5 600 | 5 600 | 5 450 | 6 050 | |
| 100,000 | 7 200 | 7 200 | 7 200 | 7 250 | 8 100 | |
| 200,000 | 9 200 | 9 200 | 9 200 | 9 350 | 10 600 | |
| 500,000 | 12 400 | 12 400 | 12 400 | 12 500 | 14 500 | |
| 800,000 | 13 600 | 13 600 | 13 600 | 14 250 | 16 750 | |
| 1,000,000 | 15 200 | 15 200 | 15 200 | 15 050 | 17 850 | |
| 1,500,000 | 15 900 | 15 900 | 15 900 | 16 550 | 19 950 | |
| 2,000,000 | 18 300 | 18 300 | 18 300 | 17 550 | 21 450 | |
| 5,000,000 | .. | .. | .. | 20 550 | 26 300 | |
| |
STANDARD ERRORS OF PERSON ESTIMATES - 1998-2003 |
| |
| 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | |
| Size of estimate | no. | no. | no. | no. | no. | no. | |
| |
| 2,000 | .. | 1 400 | 1 500 | 900 | 1 570 | 1 020 | |
| 5,000 | 2 400 | 2 500 | 2 600 | 1 550 | 2 600 | 1 740 | |
| 10,000 | 3 400 | 3 800 | 3 800 | 2 250 | 3 770 | 2 550 | |
| 20,000 | 4 800 | 5 500 | 5 500 | 3 300 | 5 400 | 3 670 | |
| 50,000 | 7 000 | 8 400 | 8 500 | 5 200 | 8 600 | 5 760 | |
| 100,000 | 9 200 | 11 300 | 11 400 | 7 250 | 12 000 | 7 910 | |
| 200,000 | 12 200 | 14 700 | 14 800 | 9 900 | 16 600 | 10 640 | |
| 500,000 | 17 200 | 19 900 | 19 900 | 14 550 | 25 500 | 15 280 | |
| 800,000 | 20 400 | 22 700 | 22 800 | .. | .. | .. | |
| 1,000,000 | 21 900 | 24 100 | 24 100 | 19 150 | 34 000 | 19 630 | |
| 1,500,000 | 25 500 | 26 500 | 26 600 | .. | .. | .. | |
| 2,000,000 | 27 800 | 28 200 | 28 300 | 24 700 | 46 000 | 24 700 | |
| 5,000,000 | 37 700 | .. | 33 300 | 33 700 | 65 000 | .. | |
| |
8 The standard error can also be expressed as a percentage of the estimate. This is known as the relative standard error (RSE). The RSE is determined by dividing the standard error of the estimate SE(x) by the estimate x and expressing it as a percentage. That is: RSE(x)=100*SE(x)/x (where x is the estimate). The RSE is a measure of the percentage error likely to have occurred due to sampling.
9 The tables below illustrate the RSE ranges for the size of estimates for tables in this report. Only estimates with RSEs less than 25% are considered sufficiently reliable for most purposes. Household and person estimates with an RSE between 25% and 50% are preceded by an asterisk (e.g. *3.4) to indicate they are subject to high SEs and should be used with caution. Household and person estimates with an RSE greater than 50% are preceded by a double asterisk (e.g. **0.3), are considered too unreliable for general use.
ESTIMATES WITH RELATIVE STANDARD ERRORS OF 25% AND 50%, Households - 1998-2002 |
| |
| 1998 | 1999 | 2000 | 2001 | 2002 | |
| no. | no. | no. | no. | no. | |
| |
| Estimates with RSE of 25% | 2 784 | 2 912 | 2 912 | 2 500 | 2 808 | |
| Estimates with RSE of 50% | 2 117 | 2 117 | 2 117 | 962 | 1 203 | |
| |
ESTIMATES OF RELATIVE STANDARD ERRORS OF 25% AND 50%, persons - 1998-2003 |
| |
| 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | |
| |
| Estimates with RSE of 25% | 4 845 | 5 379 | 5 363 | 8 087 | 23 500 | 10 468 | |
| Estimates with RSE of 50% | 2 448 | 2 500 | 2 595 | 1 544 | 5 441 | 2 172 | |
| |
PROPORTIONS AND PERCENTAGES
10 Proportions of a total and percentages formed from the ratio of two estimates are subject to sampling error. The size of the error depends on the accuracy of both the numerator and denominator. The formula for the relative standard error of a proportion or percentage for all four surveys is:
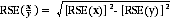
MOVEMENTS
11 Particular care should be taken when comparing estimates over time. It is not correct to assume that an apparent difference between estimates is actually significant. Such an estimate is subject to sampling error. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
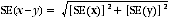
12 While this formula will only be relevant for differences between separate and uncorrelated characteristics or subpopulations, it is expected to provide a good approximation for all differences likely to be of interest in this report.
DATA ISSUES
Imputation of Data for persons aged 65 years or over for Survey of Education, Training and Information Technology, 2001 (SETIT)
13 The scope for the General Social Survey (GSS) and the Population Survey Monitor (PSM) were persons aged 18 years and over. It should be noted that the scope for Survey of Education, Training and Information Technology (SETIT) was restricted to persons aged 15-64 years. As a result, data were not collected from households where all usual residents were aged 65 years or over living in households with persons who were in scope for this particular survey.
14 To enable comparisons at the household and person levels between the other surveys in this report and SETIT, the 2001 SETIT data includes an imputed estimate for households and persons that were considered out of scope of the SETIT due to the exclusion of persons aged 65 years or over.
15 The imputation used data for persons aged 65 years or over that was collected in 2000 from the PSM. Two adjustments were made to the 2000 data. The first adjustment accounted for known changes in the numbers of persons aged 65 years or over. The second adjustment accounted for expected changes in the proportions of persons aged 65 years or over who had access to a computer or to the Internet at home at a household level, and who had used a computer or the Internet at a person level. These expected changes were calculated by assuming that the changes that occurred between 2000 and 2001 would be the same size as the changes between 1999 and 2000. All the adjustments were calculated at the state and capital city/balance of state levels.
16 The estimates in the 2001 results should be treated with some caution, as the adjustments may not accurately reflect the true changes that occurred between 2000 and 2001. However, the contribution from the imputed data to the total estimates is relatively small. For example, persons aged 65 years or over contributed about 3% to the total estimate of computer use by all persons.
Revision of estimates for 1998-2000
17 The methodology originally used to create the estimation weights for the PSM differed to that used for the SETIT and the GSS. Both the PSM and the SETIT methodologies benchmarked person level weights from the surveys to population estimates produced by the ABS. However, the SETIT methodology also benchmarked household level weights to household population estimates produced by the ABS. Benchmarking the weights to population estimates reduces the likelihood that differences observed over time in the survey estimates for particular groups are due to sampling error rather than actual changes.
18 In order to improve the comparability of the PSM and the SETIT estimates, the PSM data have been recalculated using the household and person-level weighting methodology applied to SETIT data. However, readers should note that some differences remain between the PSM and SETIT methodologies even after the revision (see Explanatory Notes). Consequently, readers should exercise caution when interpreting differences in estimates between 2000 and 2001 as these differences may be partly explained by the change in the survey vehicle from the PSM to the SETIT.
Estimate of expenditure on Internet transactions 2001-2002
19 In 2001, persons were asked to specify the value of their Internet purchases of goods and services within the following ranges:
$0-50, $51-$100, $101-$250, $251-$500, $501-$1,000, More than $1,000.
20 In 2002, persons were asked to specify the value of their Internet purchases of goods and services within the following ranges:
$0-50, $51-$100, $101-$250, $251-$500, $501-$1,000, $1,001-$2000, $2001-$5000, $5001-$10,000, More than $10,000.
21 The 2002 data has been collapsed into the following ranges for comparison purposes:
$0-250, $251-$500, $501-$1,000, More than $1,000.
22 As a result of the different value ranges between 2001 and 2002, the data is not directly comparable.
EDUCATIONAL CLASSIFICATIONS
23 In 2001, the Australian Standard Classification of Education (ASCED) (cat. no. 1272.0) replaced the ABS Classification of Qualifications (ABSCQ) (cat. no. 1261.0) . The ASCED is a new national standard classification which can be applied to all sectors of the Australian education system including schools, vocational education and training, and higher education. Readers should note that the categories presented in the tables for the classification 'Level of highest educational attainment' are not comparable to the categories presented for the classification 'Qualifications' used in 1998 to 2000.
24 The major groups of the ASCED classification have been aggregated to increase the reliability of estimates within each category.
25 The nine broad Levels of Education in ASCED are:
1 Postgraduate Degree Level
2 Graduate Diploma and Graduate Certificate Level
3 Bachelor Degree Level
4 Advanced Diploma and Diploma Level
5 Certificate Level
6 Secondary Education
7 Primary Education
8 Pre-primary Education
9 Other Education
26 These nine broad levels of ASCED have been collapsed into the following categories:
Year 12 or lower (ASCED groups 6, 7, 8 and 9)
Trade/other certificate (ASCED group 5)
Diploma/advanced diploma (ASCED group 4)
Bachelor degree or higher (ASCED groups 1, 2 and 3)
OCCUPATION CLASSIFICATION
27 The Australian Standard Classification of Occupations (ASCO) is used in all Australian Bureau of Statistics (ABS) censuses and surveys where occupation data are collected. The categories at the Major Group level of ASCO are:
1 Managers and Administrators
2 Professionals
3 Associate Professionals
4 Tradespersons and Related Workers
5 Advanced Clerical and Service Workers
6 Intermediate Clerical, Sales and Service Workers
7 Intermediate Production and Transport Workers
8 Elementary Clerical, Sales and Service Workers
9 Labourers and Related Workers
28 In this publication, the major group levels of the ASCO classification have been aggregated to increase the reliability of estimates within each category. These, in turn, are collapsed into the following categories:
Managers, administrators and professionals (ASCO groups 1, 2 and 3)
Clerical, sales and service workers (ASCO groups 5, 6 and 8)
Tradespersons, transport workers, labourers and related workers (ASCO groups 4, 7 and 9)
 Print Page
Print Page
 Print All
Print All