TECHNICAL NOTE
RELIABILITY OF ESTIMATES
1 Estimates from the LFS, as with data from all surveys, are subject to error. The data presented in this publication are subject to two sources of error:
- non-sampling error, which arises from imperfections in reporting, recording or processing of data that can occur in any survey or census.
- sampling error, which occurs because data were obtained from a sample rather than the entire population.
NON-SAMPLING ERROR
2 The main sources of non-sampling error are response errors and non-response bias. These may occur in any enumeration whether it is a full count or a sample.
3 Response errors include errors on the part of both respondents and interviewers. These reporting errors may arise through inappropriate wording of questions, misunderstanding of what data are required, inability or unwillingness to provide accurate information, and mistakes in answers to questions.
4 Non-response bias arises because the persons for whom no response is available may have different characteristics in relation to labour market behaviour than persons who responded in the survey.
5 Non-sampling errors are difficult to quantify in any collection. However, every effort is made to minimise these errors in the LFS by careful design of questionnaires, intensive training and supervision of interviewers and efficient operating procedures. Non-response bias is minimised by call-backs to those households which do not respond, and is compensated for in the estimation process.
6 There are a number of other issues associated with collecting information from Indigenous persons in communities in remote areas. Although special procedures are used in some Indigenous communities, there may still be some cultural and practical difficulties in applying standard labour force concepts in these communities. Operational issues include the high turnover of trained interviewers in remote areas, the seasonal fluctuations in population numbers as well as in employment opportunities, and high population mobility.
7 Responses in the LFS may be given by any responsible adult in each selected household. Reporting errors may arise when the respondent provides information for another member of the household without being fully aware of their labour force details. Although this is a minor issue for the survey in general, the higher mobility of Indigenous household members may affect the reporting on details such as active job search or availability for work.
SAMPLING ERROR
8 The LFS estimates are based on information obtained from a sample of the population, and are subject to sampling error. Sampling error is the difference between the estimate obtained from a particular sample and the value that would have been obtained if the whole population were enumerated under the same procedures (referred to as the 'population value').
Standard error
9 The most commonly used measure of sampling error is the standard error (SE). This measure indicates the extent to which a survey estimate is likely to deviate from the true population value by chance. There are about two chances in three (67%) that the sample estimate will differ by less than one standard error from the estimates that would have been obtained if all dwellings had been included in the survey, and about nineteen chances in twenty (95%) that the difference will be less than two standard errors.
10 The magnitude of the sampling error depends on the sample design, the sample size and the population variability. The larger the sample on which the estimates are based, the smaller the sampling error. The main contribution to sampling error for the Indigenous labour force estimates is the sample size.
11 Movements in the level of an estimate are also subject to sampling variability. The standard error of the movement depends on the levels of the estimates from which the movement is obtained rather than the size of the movement. The standard errors for both level estimates and movements between annual estimates are shown in the tables in this section. The standard errors have been derived using the group jackknife method.
Relative standard error
12 Another measure of sampling error is the relative standard error, which is obtained by expressing the standard error as a percentage of the estimate to which it refers. The smaller the sample estimate, the higher the relative standard error. The small sample size of Indigenous persons results in estimates of labour force characteristics which are considerably less precise and less stable than comparable aggregate estimates for non-Indigenous persons. This is reflected in the relatively high standard errors for the survey estimates derived for Indigenous persons.
13 Very small estimates are subject to such high standard errors, relative to the size of the estimate, as to detract seriously from their value for most reasonable uses. In the tables in this publication, only estimates with relative standard errors of 25% or less, are considered sufficiently reliable for most purposes. Accordingly, while included in the tables, estimates with relative standard errors greater than 25% are preceded by an asterisk (e.g. *3.4), to indicate they are subject to high standard errors and should be used with caution.
14 Proportions and percentages (for example, unemployment rates) formed from the ratio of two estimates are also subject to sampling error. The size of the error depends on the accuracy of both the numerator and the denominator. A formula to approximate the RSE of a proportion or percentage is:
15 This formula is only valid when x is a subset of y.
EXAMPLES OF CALCULATIONS
Level standard errors
16 As an example of the calculation and use of standard errors, consider the estimate of 160,300 Indigenous persons employed in 2006. The standard error for this estimate is 6,600 (see Table L1). This indicates that there are about two chances in three that the true value (the number that would have been obtained if the whole population had been included in the survey) is within the range 153,700 to 166,900 (that is, 160,300 + or - 6,600). There are about 19 chances in 20 that the true value is in the range 147,100 to 173,500 (that is, 160,300 + or - 13,200).
Movement standard errors
17 Standard errors can also be used to interpret the reliability of annual movement estimates. For example, in 2005 there were an estimated 65,000 Indigenous females in employment, increasing to 71,900 in 2006 (a movement of 6,900). The associated standard error for the movement estimate is 4,300 (see Table M1) . This indicates that there are two chances in three that the true value of the movement is within the range 2,600 to 11,200 (that is, 6,900 + or - 4,300). There are about 19 chances in 20 that the true value is in the range -1,700 to 15,500 (that is, 6,900 + or - 8,600).
Differences between estimates
18 Published estimates may also be used to calculate the difference between two survey estimates (numbers or percentages). Such an estimate is subject to sampling error. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
19 While this formula will only be exact for differences between separate and uncorrelated characteristics or subpopulations, it is expected to provide a good approximation for all differences likely to be of interest in this publication.
20 For example, in 2006, the participation rate of Indigenous males was 66.3%, 14.7 percentage points higher than the rate of 51.6% for Indigenous females. The approximate standard error of the difference between these two estimates can be calculated as follows:

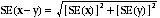
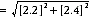
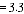
 Print Page
Print Page
 Print All
Print All