TECHNICAL NOTE DATA QUALITY
INTRODUCTION
1 Since the estimates in this publication are based on information obtained from occupants of a sample of dwellings, they are subject to sampling variability. That is, they may differ from those estimates that would have been produced if all dwellings had been included in the survey. One measure of the likely difference is given by the standard error (SE), which indicates the extent to which an estimate might have varied by chance because only a sample of dwellings was included. There are about two chances in three(67%) that a sample estimate will differ by less than one SE from the number that would have been obtained if all dwellings had been included, and about 19 chances in 20 (95%) that the difference will be less than two SEs. Another measure of the likely difference is the relative standard error (RSE), which is obtained by expressing the SE as a percentage of the estimate.
2 Due to space limitations, it is impractical to print the SE of each estimate in the publication. Instead, a table of SEs is provided to enable readers to determine the SE for an estimate from the size of that estimate (see table T1). The SE table is derived from a mathematical model, referred to as the 'SE model', which is created using data from a number of past Labour Force Surveys. It should be noted that the SE model only gives an approximate value for the SE for any particular estimate, since there is some minor variation between SEs for different estimates of the same size.
3 The LFS sample size in September 2008 was approximately one-third smaller than the sample size in September 2007. This is due to an 11% sample reduction that was implemented from November 2007 to June 2008 based on the 2006 sample design, and an additional 24% sample reduction implemented in July 2008. In combination, the two sample reductions are expected to increase the standard errors for estimates from the supplementary surveys by approximately 22% at the broad aggregate level, relative to the 2001 sample design (standard errors will vary at lower aggregate levels). Detailed information about the sample reduction is provided in Information Paper: Labour Force Survey Sample Design, Nov 2007 (Second edition) (cat. no. 6269.0).
CALCULATION OF STANDARD ERROR
4 An example of the calculation and the use of SEs in relation to estimates of persons is as follows. Table 1 shows that the estimated number of people in Australia who were discouraged job seekers was 73,900. Since the estimate is between 50,000 and 100,000, table T1 shows that the SE for Australia will lie between 4,450 and 5,850 and can be approximated by interpolation using the following general formula:

5 Therefore, there are about two chances in three that the value that would have been produced if all dwellings had been included in the survey will fall within the range 68,800 to 79,000 and about 19 chances in 20 that the value will fall within the range 63,700 to 84,100. This example is illustrated in the following diagram.

In general, the size of the SE increases as the size of the estimate increases. Conversely, the RSE decreases as the size of the estimate increases. Very small estimates are thus subject to such high RSEs that their value for most practical purposes is unreliable. In the tables in this publication, only estimates with RSEs of 25% or less are considered reliable for most purposes. Estimates with RSEs greater than 25% but less than or equal to 50% are preceded by an asterisk (e.g.*3.2) to indicate they are subject to high SEs and should be used with caution. Estimates with RSEs of greater than 50%, preceded by a double asterisk (e.g.**0.4), are considered too unreliable for general use and should only be used to aggregate with other estimates to provide derived estimates with RSEs of less than 25%.
PROPORTIONS AND PERCENTAGES
7 Proportions and percentages formed from the ratio of two estimates are also subject to sampling errors. The size of the error depends on the accuracy of both the numerator and the denominator. A formula to approximate the RSE of a proportion is given below. This formula is only valid when x is a subset of y.
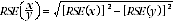 8
8 Considering the example above, of the 73,900 people who were discouraged job seekers, 39,300 or 53.2% were females. The SE of 39,300 may be calculated by interpolation as 4,100. To convert this to an RSE we express the SE as a percentage of the estimate, or 4,100/39,300=10.4%. The SE for 73,900 was calculated previously as 5,100, which converted to an RSE is 5,100/73,900=6.9%. Applying the above formula, the RSE of the proportion is:
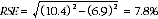 9
9 Therefore, the SE for the proportion of discouraged job seekers who were females is 4.1 percentage points (=(53.2/100)x7.8). Therefore, there are about two chances in three that the proportion of females who were discouraged job seekers was between 49.1% and 57.3% and 19 chances in 20 that the proportion is within the range 45.0% to 61.4%.
DIFFERENCES
10 Published estimates may also be used to calculate the difference between two survey estimates (of numbers or percentages). Such an estimate is subject to sampling error. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
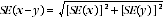 11
11 While this formula will only be exact for differences between separate and uncorrelated characteristics or subpopulations, it is expected to provide a good approximation for all differences likely to be of interest in this publication.
STANDARD ERRORS
T1 STANDARD ERRORS OF ESTIMATES |
|
 | | | | | | | | | AUST. |
| NSW | Vic. | Qld | SA | WA | Tas. | NT | ACT | SE | RSE |
| Size of estimate (persons) | no. | no. | no. | no. | no. | no. | no. | no. | no. | % |
|
| 100 | 190 | 200 | 170 | 170 | 180 | 130 | 100 | 110 | 130 | 130.0 |
| 200 | 300 | 310 | 270 | 250 | 280 | 190 | 140 | 180 | 230 | 115.0 |
| 300 | 400 | 390 | 360 | 310 | 350 | 230 | 170 | 230 | 310 | 103.3 |
| 500 | 540 | 530 | 490 | 410 | 470 | 290 | 220 | 310 | 440 | 88.0 |
| 700 | 660 | 640 | 600 | 480 | 560 | 340 | 260 | 370 | 560 | 80.0 |
| 1,000 | 810 | 770 | 740 | 570 | 670 | 390 | 310 | 430 | 700 | 70.0 |
| 1,500 | 1 010 | 950 | 920 | 680 | 810 | 460 | 380 | 500 | 910 | 60.7 |
| 2,000 | 1 180 | 1 100 | 1 060 | 770 | 920 | 510 | 440 | 540 | 1 070 | 53.5 |
| 2,500 | 1 300 | 1 200 | 1 200 | 850 | 1 000 | 550 | 500 | 550 | 1 200 | 48.0 |
| 3,000 | 1 450 | 1 350 | 1 300 | 900 | 1 100 | 600 | 550 | 600 | 1 350 | 45.0 |
| 3,500 | 1 550 | 1 450 | 1 400 | 950 | 1 150 | 600 | 600 | 600 | 1 450 | 41.4 |
| 4,000 | 1 650 | 1 500 | 1 500 | 1 000 | 1 250 | 650 | 650 | 650 | 1 550 | 38.8 |
| 5,000 | 1 850 | 1 700 | 1 650 | 1 100 | 1 350 | 700 | 750 | 700 | 1 750 | 35.0 |
| 7,000 | 2 100 | 1 950 | 1 900 | 1 250 | 1 500 | 800 | 950 | 850 | 2 050 | 29.3 |
| 10,000 | 2 450 | 2 250 | 2 150 | 1 450 | 1 700 | 950 | 1 300 | 1 100 | 2 400 | 24.0 |
| 15,000 | 2 900 | 2 600 | 2 500 | 1 700 | 2 000 | 1 200 | 1 850 | 1 450 | 2 850 | 19.0 |
| 20,000 | 3 200 | 2 900 | 2 750 | 1 950 | 2 300 | 1 400 | 2 350 | 1 700 | 3 200 | 16.0 |
| 30,000 | 3 700 | 3 350 | 3 200 | 2 400 | 2 900 | 1 750 | 3 200 | 2 100 | 3 700 | 12.3 |
| 40,000 | 4 050 | 3 700 | 3 600 | 2 800 | 3 450 | 2 050 | 3 950 | 2 350 | 4 100 | 10.3 |
| 50,000 | 4 450 | 4 050 | 4 000 | 3 150 | 3 900 | 2 250 | 4 600 | 2 500 | 4 450 | 8.9 |
| 100,000 | 6 200 | 5 850 | 5 850 | 4 500 | 5 750 | 3 100 | 7 150 | 2 850 | 5 850 | 5.9 |
| 150,000 | 7 850 | 7 500 | 7 400 | 5 400 | 7 050 | 3 700 | 9 000 | 2 850 | 6 950 | 4.6 |
| 200,000 | 9 400 | 8 950 | 8 700 | 6 100 | 8 100 | 4 150 | . . | . . | 7 950 | 4.0 |
| 300,000 | 11 850 | 11 350 | 10 700 | 7 200 | 9 750 | 4 850 | . . | . . | 9 700 | 3.2 |
| 500,000 | 15 300 | 15 250 | 13 550 | 8 650 | 12 050 | 5 800 | . . | . . | 12 650 | 2.5 |
| 1,000,000 | 20 450 | 22 450 | 17 750 | 10 750 | 15 600 | . . | . . | . . | 18 750 | 1.9 |
| 2,000,000 | 25 500 | 32 500 | 22 000 | 12 850 | 19 450 | . . | . . | . . | 27 200 | 1.4 |
| 5,000,000 | 30 600 | 51 750 | 26 950 | . . | . . | . . | . . | . . | 39 200 | 0.8 |
| 10,000,000 | 32 450 | 72 250 | . . | . . | . . | . . | . . | . . | 47 050 | 0.5 |
|
| . . not applicable |
T2 levels at which estimates have relative standard errors of 25% and 50%(a) |
|
| NSW | Vic. | Qld | SA | WA | Tas. | NT | ACT | Aust. |
| no. | no. | no. | no. | no. | no. | no. | no. | no. |
|
| RSE of 25% | 9 700 | 8 300 | 7 900 | 4 200 | 5 600 | 2 100 | 1 500 | 2 200 | 9 400 |
| RSE of 50% | 2 800 | 2 400 | 2 300 | 1 300 | 1 700 | 700 | 400 | 800 | 2 300 |
|
| (a) Refers to the number of people contributing to the estimate. |
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All