Turning your information into Census data
The information provided on the Census form goes through a series of steps before it is ready to be released as statistics in a variety of products and articles. Typically, it takes around ten months from the date of Census night to release of detailed data from the Census. For the 2016 Census there was the earliest release ever of information from the Census in April 2017 (eight months after the Census). This release provided a preview of key characteristics of a typical Australian in 2016, and the typical person in each State and Territory.
This diagram illustrates the path that the information goes through as it is processed prior to release.
Processing your information
The diagram above shows the different pathways for the different types of forms.
Processing the information received from each person and household in Australia includes many steps, from receipt of online or paper forms through to creating a final set of Census data that can be used to create a range of products and articles for publication.
Online forms and data from administrative files were able to be loaded directly into the system used to process Census data.
Paper forms needed to undertake an extra step in their processing and usually travelled via Australia Post trucks to the ABS’ Secure Data Capture Centre located in Dandenong, Victoria.
Data Capture
The Data Capture Centre received and processed all of the
paper Census forms as they were submitted. This included:
- confirming receipt of forms
- opening envelopes and preparing the forms for scanning
- scanning the forms and converting it to electronic data
- repairing information not able to be captured accurately through scanning or to transcribe information from field officer materials.
The Data Capture Centre was also responsible for the secure destruction of all paper forms and other materials once the information was captured.
As the information progresses through the processing system it undergoes a number of different processes to help turn it into useful data, including coding, imputation, derivations, editing and data assurance.
Coding
Any Census questions that allows a response to be written or typed by respondents, such as questions about occupation, industry, language spoken at home, birthplace, usual address and ancestry, require coding to the correct category in the relevant standard classifications. The classifications for each of these can be found in the
2016 Census Dictionary. There are three types of coding;
· Automatic – most responses have sufficient information for a computer system to code directly to the classification without clerical involvement
· Computer assisted – where programs are used to help define the information to a level of detail able to be coded to the classification
· Manual – where Census coding staff review the information provided to determine the best fit to the classification
Imputation
Sometimes the ABS uses a statistical process called ‘Imputation’. This is a process that adds information to some of the data where it is deemed to be missing. There are two instances where the process of imputation is used in the Census;
- Where no Census form has been returned for a dwelling that is identified by a Census Field Officer to have been occupied on Census night.
In this case, people are imputed into the dwelling.
The numbers and key demographic characteristics (age, sex, marital status and usual address) for people imputed into non-responding private dwellings are determined by using information from the responses that people provided in similar dwellings in the area*.
The numbers and key demographic characteristics for people imputed into non-private dwellings (hotels, boarding houses, etc.) are determined by using information from people who did respond within the same dwelling and aggregate information provided by the non-private dwelling.
- Where people have returned a form but not responded to all the questions.
In this case, only information for the key demographic items (age, sex, marital status and place of usual residence) are imputed.
For more information about imputation please refer to the
2016 Census Dictionary.
* This is a change in 2016. In 2011, for some non-responding private dwellings Census Field Officers were able to obtain an estimate of the numbers of males and females staying in the dwelling and this was used as credible information to draw upon during the imputation process. This was not available in 2016 under the new collection method.
Derivations
In some cases the responses from one or more questions are used to derive the value for particular variables. For example, where people have provided only their date of birth (but not their age), their age is calculated (or derived) from their date of birth. Another example is where responses to labour force status and relationship in household are used to derive a variable that describes the labour force status of parents.
Households and families
The information provided about an individual’s relationship with other people in the household was used to create a classification of their family and household unit (for example, couples with or without children, or single parent families, people living alone or group households). Information provided about any people temporarily absent from the household on Census night also contributed to the formation of the family and household classifications.
Editing
There are a small number of common sense rules that are applied to the information provided by respondents to ensure coherent and consistent output data. These edits are limited to where the answers to different questions for the same person conflict with each other according to Census definitions. For example, if someone mistakenly states that they are 5 years old and that they are also in a registered marriage their record is flagged for investigation and resolution to ensure it complies with the definitions of these items (please refer to each data item in the 2016 Census Dictionary for information about each item and it’s applicable population).
Data Assurance
Throughout processing, a number of checks are undertaken to ensure that the data are coherent, consistent and an accurate representation of the responses received. These checks included;
· Comparison of the data with previous Censuses
· Comparison of the data with other sources of information including Survey of Income and Housing, Migration data, and Building Approvals data.
· Looking for and verifying expected changes in the data with real world changes (for example, where new suburbs have been created between Censuses, or where natural disasters impacted dwelling numbers in specific areas).
The work undertaken to quality assure the data is used to inform individual quality statements for each of the data item (refer to Data Quality Statements in the
Understanding the data chapter of this publication).
For more information about Managing Census Quality please refer to the
2016 Census Dictionary.
Creating a data file
After every individual’s information has gone through all the processes outlined above it is brought together into one data file. This data file can then be used to create articles and various output products which the public can access to look at and understand Census data. It is also the step where confidentiality, or protection of respondents’ data, is applied, including the removal of names and addresses.
Confidentiality – protecting your data
As with all previous Censuses, the ABS takes steps to ensure all data is kept confidential. The ABS is committed to protecting the personal information it collects. Not only does the ABS have strong legislative protections that safeguard the secrecy of an individual's information, we have a proud 100-year history of maintaining community trust in the way it collects, uses, discloses and stores personal information collected in the Census.
What does Confidentiality mean?
Confidentiality is about ensuring the personal information the ABS has collected is kept secret. The ABS uses a number of processes and methods to ensure the information released is consistent with our secrecy obligations. The ABS never has and never will release identifiable Census data. Key measures to safeguard information include strong encryption of data, restricted access on a need-to-know basis and monitoring of staff data access, including regular audits.
In accordance with the Census and Statistics Act 1905 all Census data, including in QuickStats, Community Profiles, DataPacks and TableBuilder, is subjected to a confidentiality process called perturbation before release. This includes the information found in Census of Population and Housing: Reflecting Australia - Stories from the Census and all publications that use Census data. This confidentiality process is undertaken to stop the release of information that may allow for the identification of particular individuals, families, households, or businesses.
Perturbation
The ABS has developed a technique to adjust counts to maintain confidentiality of information. This technique, known as perturbation, makes small adjustments to all counts - including totals - to prevent any identifiable data about individuals being released. These adjustments result in small introduced random errors and can mean that the rows and columns of a table do not sum to the displayed totals. However, the confidentiality technique is applied in a controlled manner that ensures the information value of the table as a whole is not significantly affected. Further information on the methodology of perturbation can be found in this paper.
Perturbation can be a source of frustration to users because rows and columns do not add to totals, but this technique is implemented to protect personal information. Most tables reporting basic statistics will not show significant discrepancies due to perturbation. However, as the degree of complexity of a table increases, the need for perturbation remains and it will continue to be used in the release of 2016 Census data.
For 2006 and 2011 Census data, an additional 'additivity step' was applied that made further small adjustments to each table to ensure rows and columns added to totals. This extra adjustment meant that comparisons between tables which contained similar data items had minor discrepancies. In addition, as the tables at different geographic levels are adjusted independently, tables at the higher geographic level may not be equal to the sum of the tables for the component geographic units. For 2016 Census data this additivity step has been removed in order to address these inconsistencies. For consistency and interpretability, the 2006 and 2011 data that appears in the following 2016 products have been re-calculated without additivity - Time Series Community Profile, DataPacks and the time series comparisons in QuickStats.
Interpreting the data
Perturbation has very little impact on Census data.
This is because it is applied consistently to the data so the same information will always have the same adjustment applied, and it is very small in magnitude. For example, a count of 15-24 year old males in New South Wales will have the same perturbation applied regardless of how a table with this data is constructed. However, the count in QuickStats may in rare cases differ marginally from the count in Community Profiles and DataPacks because the data in these products are recoded for presentation purposes.
The best number to use will always be the count that most directly corresponds to the information you require. It is not recommended that you derive information by summing across a row or down a column, as this increases the instances where perturbation may impact on the output. For instance, if you are interested in the count of 15-24 year old males in New South Wales, the total count will be the best figure to use, not the sum in individual years of males in New South Wales.
When calculating proportions, percentages or ratios from cross-classified or small area tables, the random adjustments introduced by perturbation can be ignored except when very small counts are involved, in which case the impact on percentages and ratios can be relatively significant. No reliance should be placed on small counts (that is, counts of 20 or less). Aside from the effects of the confidentiality process, Census non-response and possible respondent and processing errors have greatest relative impact on these small counts.
With the removal of the additivity step for 2016 Census data, comparisons over time should be made using the 2016 time series products where possible. Comparisons between 2011 QuickStats and 2016 QuickStats will compare one product where additivity has been applied and another where it hasn't. Whilst this will not have a significant impact on the differences observed over time, the most correct approach is to use the 2016 time series products. The 2011 Census data products will not be re-released with the additivity step removed.
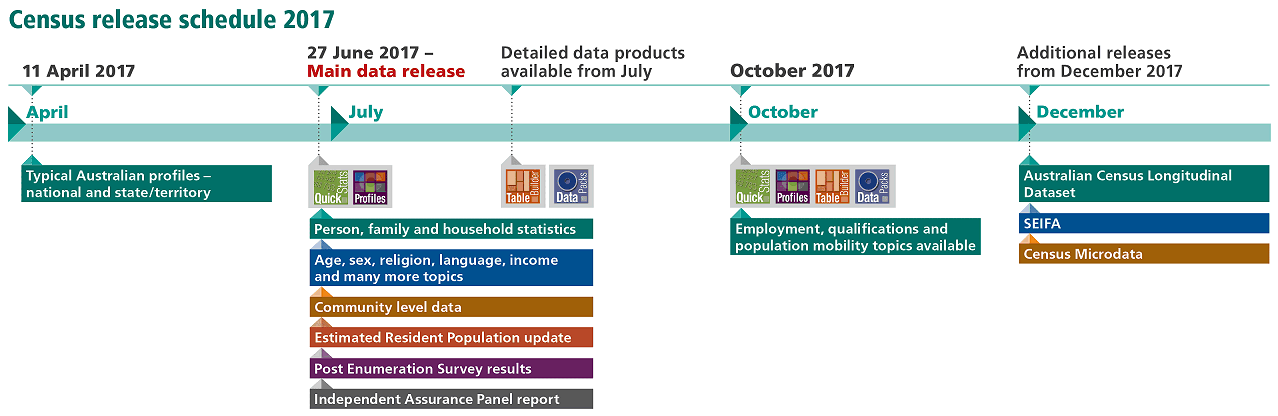
Output products
The 2016 Census data is released through a variety of products with different degrees of detail and complexity.
 QuickStats is a fast, simple way for users to understand an area at a glance and is intended for anyone wanting quick summary information. Available June 27th 2017
QuickStats is a fast, simple way for users to understand an area at a glance and is intended for anyone wanting quick summary information. Available June 27th 2017
 Community Profiles are excellent tools for researching, planning and analysing geographic areas for a number of social, economic and demographic variables. Available June 27th 2017
Community Profiles are excellent tools for researching, planning and analysing geographic areas for a number of social, economic and demographic variables. Available June 27th 2017
 TableBuilder allows users to build their own tables using Census data items. It is designed for users who have knowledge of Census concepts and some experience using Census data. Available July 4th 2017
TableBuilder allows users to build their own tables using Census data items. It is designed for users who have knowledge of Census concepts and some experience using Census data. Available July 4th 2017
 Census DataPacks contain comprehensive data about people, families and dwellings for all available geographic areas, with associated Geographic Information System digital boundary files. Available July 12th 2017
Census DataPacks contain comprehensive data about people, families and dwellings for all available geographic areas, with associated Geographic Information System digital boundary files. Available July 12th 2017
Analytical articles use Census data to explore a wide range of topics, such as cultural diversity, same-sex families, migration flows, the ageing population and more. Available progressively from June 27th 2017
Australian Census Longitudinal Dataset (ACLD) – The second issue of the ACLD brings together a five per cent random sample of data from the 2006, 2011 and 2016 Censuses to create a research tool for exploring how Australian society is changing over time. Available February 2018.
Census Microdata, for advanced users of Census data, is released under strict access conditions. A Census Sample File is made available containing a small, random sample of households and non-private dwellings that has been confidentialised to protect the privacy and security of personal data. It will contain Census characteristics for person, family and dwelling variables. Available 2018
Socio-Economic Indexes for Areas (SEIFA) – SEIFA use Census data to rank areas in Australia according to relative socio-economic advantage and disadvantage. Available March 2018
Customised data – ABS analysts can extract Census data to your unique requirements and provide data in a range of formats to meet your needs. This service is available to anyone. Charges do apply. The ABS is taking orders now for Census data. Call 1300 135 070 to discuss your Census data needs.
Phased release of variables
There are two main phases to release all Census data items.
The first release phase includes the majority of data items and is available on June 27th 2017.
The second release phase includes employment, qualifications and population mobility (transport and previous address) and will be available in October 2017. This type of information needs extra time to process because of its complexity and will be released through further additions to Quickstats,
Community Profiles, TableBuilder and DataPacks.
Details about the availability of data items is listed in the 2016 Census Dictionary.
Uses of Census Data
Census is the definitive and often only open source of data on small population groups and small geographic areas across the whole of Australia. Data collected in the 2016 Census will underpin $500 billion of funding distribution over the next five years. It's also critical to the setting of Commonwealth, state and local electoral boundaries. Census data is also a key data source for homelessness estimates, research, policy development, service delivery and evaluation.
Data Integration
While Census Data has value in its own right, when it is linked to other datasets it provides fresh new insights into policy issues.
Since 2006, the ABS has enhanced the value of Census data through integrating unit record data with other ABS and non-ABS datasets to create new datasets for statistical and research purposes. Data integration will continue to be a central element of the Census and is an increasingly important element of effectively and efficiently delivering the broader ABS work program.
Previous integration initiatives undertaken by the ABS have successfully demonstrated that linking Census data with other datasets provides new insights into areas and groups of interest within Australian society, such as education, migrants and Aboriginal and Torres Strait Islander peoples. These initiatives have contributed to a richer statistical view of Australian society and an improved evidence base for decision making for the community, researchers and policy makers, in a cost effective way.
The 2011 Census data integration projects have demonstrated the potential of data integration to replace direct collection, to develop new datasets (including longitudinal datasets) and to improve the quality of key estimates derived from administrative sources. These projects included the creation of the Australian Census and Migrants Integrated Dataset, the 2011 Census to Vocational Education and Training in Schools dataset, the Australian Census Longitudinal Dataset (ACLD) and the Indigenous Mortality Project. The initial release of the ACLD after the 2011 Census followed the journeys of around one million people across the 2006 and 2011 Censuses and created a research tool for exploring how Australian society is changing over time. Following completion of 2016 Census processing, the ACLD will be extended to include the 2016 Census and will offer insights into the dynamics and transitions that drive social and economic change over time, as well as providing insights into how these vary for diverse population groups and geographies. For more information on 2016 data integration, please refer to Information Paper: Census of Population and Housing - Products and Services, 2016.
The integration of 2016 Census data with other datasets will continue the production of new statistical outputs and enduring datasets, whilst keeping the privacy and confidentiality of all Australians at the centre of all stages of these projects. All personal information used in the Census and data integration projects is kept secure and confidential, in keeping with legislative requirements and ABS policies. For further information, see the section on Legal authority, confidentiality and privacy in the Census of Population and Housing: Nature and Content, 2016 publication.
Census Time Capsule
The 2016 Census again gave people the option to have their complete Census responses held securely by the National Archives of Australia for 99 years before being released for use by future generations of family historians and other researchers. The personally-identified Census information held by the National Archives of Australia is not available for any purpose (including to courts and tribunals) within the 99 year closed access period.
For more information on this initiative, see the Census Time Capsule section in Census of Population and Housing: Nature and Content, 2016.
 Print Page
Print Page
 Print All
Print All