TECHNICAL NOTE SAMPLING VARIABILITY
ESTIMATION PROCEDURE
1 Estimates derived from this survey were obtained using a post-stratification procedure. Post-stratification is a method of stratifying or dividing a sample into groups after the responses have been received. It is used to improve the quality of results through stratifying by variables that were not used at the time of sample design. In this survey the procedure ensured that the survey estimates for persons conformed to independent estimates of the population by age, sex and part of state, rather than the distribution among respondents.
RELIABILITY OF ESTIMATES
2 Estimates in this publication are subject to non-sampling and sampling errors.
Non-Sampling errors
3 Non-sampling errors may arise as a result of errors in the reporting, recording or processing of the data and can occur even if there is a complete enumeration of the population. Non-sampling errors can be introduced through inadequacies in the questionnaire, non-response, inaccurate reporting by respondents, errors in the application of survey procedures, incorrect recording of answers and errors in data entry and processing.
4 It is difficult to measure the size of the non-sampling errors. The extent of these errors could vary considerably from survey to survey and from question to question. Every effort is made to minimise these errors by the careful design of questionnaires, training and supervision of staff and development of efficient data processing procedures.
Sampling errors
5 Sampling errors are the errors which occur by chance because the data were obtained from a sample, rather than the entire population.
ESTIMATES OF SAMPLING ERROR
6 One measure of the variability of estimates which occurs as a result of surveying only a sample of the population is the standard error (see table on page 20).
7 There are about 2 chances in 3 (67%) that a survey estimate will differ by less than one standard error from the number that would have been obtained if all persons had been included in the survey. There are about 19 chances in 20 (95%) that the estimate will be less than two standard errors.
8 Linear interpolation is used to calculate the standard error of estimates falling between the sizes of estimates listed in the table.
9 The standard error (SE) can also be expressed as a percentage of the estimate. This is known as the relative standard error (RSE). The RSE is determined by dividing the standard error of an estimate SE(x) by the estimate x and expressing it as a percentage. That is - (where x is the estimate)
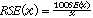
10 An example of the calculation and use of standard errors for estimates of persons follows. Table 1 shows that the estimated number of persons aged 18 years or over in NSW who had provided care in the six months to October 2005 was 2,416,500. Since the estimate is between 2,000,000 and 3,000,000 the standard error (as shown in the table on page 20) will be between 27,316 and 32,464 and can be approximated as 29,460 using linear interpolation. Therefore, there are 2 chances in 3 that the value that would have been obtained, had all persons been included in the survey, lies between 2,387,040 and 2,445,960. Similarly, there are about 19 chances in 20 that the value lies between 2,357,580 and 2,475,420.
11 Proportions and percentages formed from the ratio of two estimates are also subject to sampling error. The size of the error depends on the accuracy of both the numerator and the denominator. The formula for the relative standard error (RSE) of a proportion or percentage is -
12 Only estimates with relative standard errors of 25% or less, and percentages based on such estimates, are considered sufficiently reliable for most purposes. However, estimates and percentages with a larger RSE have been included, preceded by * (RSE between 25% and 50%) or ** (RSE greater than 50%) to indicate that they are subject to high standard errors and should be used with caution.
STANDARD ERRORS OF ESTIMATES OF NSW PERSONS - October 2005 |
|  |
| Size of estimate | Standard error | Relative standard error | |
| (persons) | no. | % | |
| |
| 1 000 | 635 | 63.5 | |
| 1 500 | 796 | 53.1 | |
| 2 000 | 933 | 46.6 | |
| 2 500 | 1 054 | 42.1 | |
| 3 000 | 1 163 | 38.8 | |
| 3 500 | 1 264 | 36.1 | |
| 4 000 | 1 358 | 34.0 | |
| 5 000 | 1 531 | 30.6 | |
| 8 000 | 1 962 | 24.5 | |
| 10 000 | 2 205 | 22.0 | |
| 20 000 | 3 150 | 15.8 | |
| 30 000 | 3 866 | 12.9 | |
| 50 000 | 4 985 | 10.0 | |
| 100 000 | 6 986 | 7.0 | |
| 200 000 | 9 710 | 4.9 | |
| 300 000 | 11 727 | 3.9 | |
| 500 000 | 14 816 | 3.0 | |
| 1 000 000 | 20 201 | 2.0 | |
| 2 000 000 | 27 316 | 1.4 | |
| 3 000 000 | 32 464 | 1.1 | |
| 4 000 000 | 36 632 | 0.9 | |
| |
13 Where differences between data items have been noted in the Summary of Findings, they are statistically significant unless otherwise specified. In this publication a statistically significant difference is one where there are 19 chances in 20 that the difference noted reflects a true difference between population groups of interest rather than being the result of sampling variability.
 Print Page
Print Page
 Print All
Print All