Food consumption
In 2011-12, Australians aged 2 years and over consumed an estimated 3.1 kilograms of foods and beverages (including water) per day, made up from a wide variety of foods across the major food groups.
- On the day before interview, almost all people (97%) reported consuming foods from the Cereals and cereal products or Cereal-based products and dishes groups. Regular bread and bread rolls was the most commonly eaten type of Cereal and cereal product, being consumed by 66% of people. Ready to eat breakfast cereals were eaten by 36% of the population.
- More than eight out of ten people (85%) consumed from the Milk products and dishes group on the day prior to interview, with foods in this group providing an average 11% of the population's energy intake. Around two-thirds (68%) of people consumed Dairy milk, while almost one-third (32%) had Cheese.
- Meat, poultry and game products and dishes were consumed by around seven out of ten (69%) people on the day prior to interview, providing 14% of total energy intakes. Chicken was the most commonly consumed meat within this category with 31% either eating a piece of chicken or eating chicken as part of mixed dish. Beef was consumed by 20% (either alone or in a mixed dish). Ham was the most commonly consumed processed meat, being consumed by 12% of the population.
- Vegetable products and dishes were consumed by three-quarters (75%) of the population, with Potatoes making up around one-quarter (by weight) of all vegetables consumed. Based on people's self-reported usual consumption of vegetables, just 6.8% of the population met the recommended usual intake of vegetables.
- Fruit products and dishes were consumed by six out of ten people (60%) overall on the day before interview. Based on self-reported usual serves of fruit eaten per day, just over half (54%) met the recommendations for usual serves of fruit.
- The most popular beverages consumed were water (consumed by 87% of the population), coffee (46%), tea (38%) soft drinks and flavoured mineral waters (29%) and Alcoholic beverages (25%).
- Just over one-third (35%) of total energy consumed was from 'discretionary foods', that is foods considered to be of little nutritional value and which tend to be high in saturated fats, sugars, salt and/or alcohol. The proportion of energy from discretionary foods was highest among the 14-18 year olds (41%). The particular food groups contributing most of the energy from discretionary foods were: Alcoholic beverages (4.8% of energy), Cakes, muffins scones and cake-type desserts (3.4%), Confectionery and cereal/nut/fruit/seed bars (2.8%), Pastries (2.6%), Sweet biscuits and Savoury biscuits (2.5%) and Soft drinks and flavoured mineral waters (1.9%).
Energy and nutrients
The average energy intake was 9,655 kilojoules (kJ) for males and 7,402 kJ for females. Energy intakes were lowest among the toddler aged children who averaged 5,951 kJ and were highest among 19-30 year old males (11,004 kJ). Female energy intakes were highest among the 14-18 year olds (8,114 kJ).
- Carbohydrate contributed the largest proportion of total energy, supplying 45% on average with the balance of energy coming from fat (31%), protein (18%), alcohol (3.4%) and dietary fibre (2.2%).
- Within carbohydrates, starch contributed 24% and sugars contributed 20% of energy. The major source of total sugars (natural and added) in the diets were: Fruit (providing 16% of sugars), Soft drinks and flavoured mineral waters (9.7%), Dairy milk (8.1%), Fruit and vegetable juices and drinks (7.5%), Sugar, honey and syrups (6.5%), Cakes, muffins, scones, cake-type desserts (5.8%).
- The average daily intake of sodium from food was just over 2,404 mg (equivalent to around one teaspoon of table salt). This amount includes sodium naturally present in foods as well as sodium added during processing, but excludes the 'discretionary salt' added by consumers in home prepared foods or 'at the table'. In addition to sodium from food, 64% of Australians reported that they add salt very often or occasionally either during meal preparation or at the table, therefore the true average intake is likely to be significantly higher.
Dietary supplements
In 2011-12, 29% of Australians reported taking at least one dietary supplement on the day prior to interview. Females were more likely than males to have had a dietary supplement (33% and 24% respectively), with the highest proportion of consumers in the older age groups. Multivitamin and/or multimineral supplements were the most commonly taken dietary supplements, being consumed by around 16% of the population with Fish oil supplements taken by around 12% of the population.
Dieting
In 2011-12, over 2.3 million Australians (13%) aged 15 years and over reported that they were on a diet to lose weight or for some other health reason. This included 15% of females and 11% of males. Being on a diet was most prevalent among 51-70 year olds where 19% of females and 15% of males were on some kind of diet.
Food avoidance
In 2011-12, 17% of Australians aged 2 years or over (or 3.7 million people) reported avoiding a food type due to allergy or intolerance and 7% (1.6 million) avoided particular foods for cultural, religious or ethical reasons.
- The most common type of food intolerance reported was Cow's milk/Dairy (4.5%), followed by Gluten (2.5%), Shellfish (2.0%) and Peanuts (1.4%).
- Pork was the most commonly avoided food type (3.9%) for cultural, religious or ethical reasons, while 2.1% specified avoiding all meat.
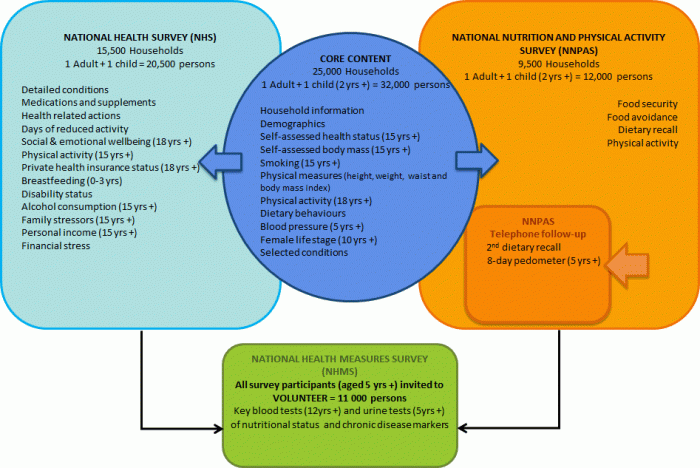
See Appendix 1 for an overview of the major food groups and the Glossary for other definitions.