Contents >>
Chapter 4 Methods of Compilation
METHODS OF COMPILATION
INTRODUCTION
4.1 Chapter 3 described the sources of GFS data and the data collection methods used. This chapter describes the next step in data processing, namely the processes of classifying, editing and consolidating the collected data to create the statistics.
4.2 The description of the compilation methodology in this chapter is targeted more towards users of the statistics than compilers. It provides a broad overview rather than a detailed description of particular procedural or operational steps. Processes are described in logical terms that do not necessarily reflect the physical structure of the computer systems underlying the processes.
GENERAL COMPILATION METHODOLOGY
4.3 GFS compilation involves transforming the accounting data of public sector units into economic statistics. This is achieved through identification and classification of the units and analysis, classification and consolidation of economic flows and stocks recorded in the units’ accounting records. The following sequence of processes is involved:
- GFS classification of units;
- GFS classification of flows and stocks;
- creating an input data base containing unit level data;
- input editing unit level data;
- data aggregation, consolidation and derivation;
- estimation on a quarterly basis only;
- output editing the data;
- creating an output data base containing aggregated data (used for dissemination of the statistics).
4.4 These processes are shown in Chart 4.1.
CHART 4.1: SCHEMATIC OVERVIEW OF GFS COMPILATION PROCESS
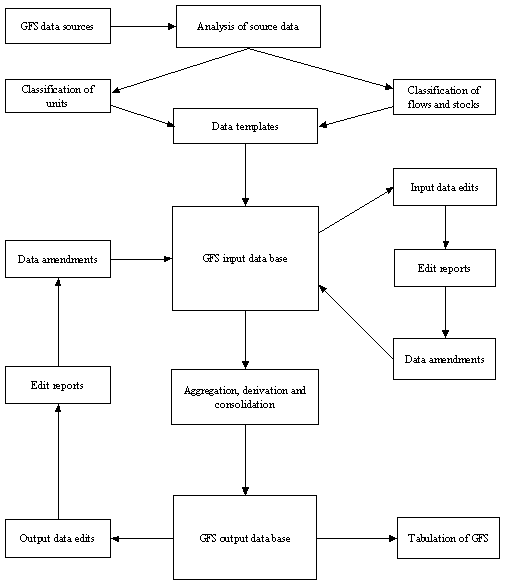
4.5 The compilation processes apply to all GFS data phases described in Chapter 3 (i.e. quarterly estimates, forward annual estimates, final annual data). However, estimation applies only to quarterly data. Quarterly statistics are compiled using a mixture of full enumeration and sampling, which requires an additional process of expanding the sample data to provide estimates for the component not covered by the sample.
DATA ANALYSIS
4.6 The first process in compilation involves transforming accounting data into GFS data. This begins with identifying the unit for which data are recorded, verifying that the unit qualifies as an enterprise unit (as described in Chapter 2) and applying the relevant GFS units classifications to the unit. The second major step is analysing the source data for the unit, which essentially amounts to linking the accounting records of flows and stocks of the unit to GFS flows and stocks classifications.
APPLICATION OF GFS UNIT CLASSIFICATIONS
4.7 As described in Chapter 2, the main GFS unit classifications are Level of government (LOG), Jurisdiction (JUR), and Institutional sector (INST).
4.8 Unit classifications are first applied at the time a unit comes into the coverage of GFS. This usually happens when a unit is created by a government in Australia, or when an existing unit is split to form more than one unit or is combined with another unit to form a new unit. Once determined, units classifications are reviewed only when major changes occur to the functions of the unit.
4.9 The classification process involves examining Acts of Parliaments (where applicable) and the unit’s financial statements (i.e. the income and expenditure (profit and loss) statement, balance sheet and cash flow statement). This process is intended to disclose the range of activities in which the unit engages and the legislative background to its creation. Such information is used to determine whether the unit qualifies as an enterprise unit and whether the enterprise falls within the scope of GFS. The information, supplemented where necessary by information obtained directly from the unit, is used to determine the classification(s) applicable to the unit.
APPLICATION OF GFS FLOWS AND STOCKS CLASSIFICATIONS
4.10 As discussed in Chapter 2, from an output perspective, the main GFS flows and stocks classifications are the economic type framework (ETF) and the government purpose classification (GPC). However, for input processing purposes, the following additional classifications are applied:
- Type of asset classification (TAC) - input items required to derive output items for stocks of non-financial assets in the statement of stocks and flows;
- Source/destination classification (SDC) - a classification that identifies: (i) for each transaction, the institutional sector and level of government (where applicable) of the unit (including non-government units) from which revenues are receivable (the source) or to which expenses are payable (the destination); and (ii) for each financial asset, the institutional sector and level of government of the unit against which the financial claim represented by the asset is held. The codes are used in the consolidation process and for producing output (e.g. grants to public non-financial corporations) that requires identification of the sector of the counterparties to transactions and stocks;
- Taxes classification (TC) - input items required to produce taxation revenue data classified by type.
4.11 For the purpose of applying the classifications, input items are grouped in the following categories:
- Operating statement items - input items required to derive output items in the operating statement;
- Cash flow statement items - input items required to derive output items in the cash flow statement;
- Reconciliation statement items - items required to reconcile items in the operating statement with items in the cash flow statement;
- Supplementary statement items - items of statistical interest that are not within the scope of the cash flow statement (e.g. acquisitions of non-financial assets);
- Intra-unit transfers other than revaluations and accrued transactions - input items identifying flows within a unit (e.g. transfers to reserves, certain provisions) other than revaluations and accrued transactions such as depreciation. Flows within a unit appear in accounting records and must be recorded in the system to ensure that a balance of debits and credits is maintained in the unit’s data. The flows cancel out in output. Revaluations and accrued transactions within units are required in output and so are not identified as intra-unit transfers;
- Revaluations and other changes in the volume of assets - input items required to derive revaluations (i.e. changes to asset values arising from price changes, including exchange rate changes) and other changes in the volume of assets in the statement of stocks and flows;
- Balance sheet items - input items required to derive output items for stocks of financial assets, liabilities and equity in the balance sheet and statement of stocks and flows.
The items included in each of the above classification components are listed in Appendix 3 and are not discussed in detail here.
4.12 Application of the flows and stocks classifications involves examining flow and stock items recorded in a unit’s accounting records and entering against each item the appropriate classification code(s) from each of the relevant classifications. A single item may have several codes entered against it. For example, an expense item will carry (at least) an ETF code to indicate the type of expense, a source/destination code to indicate the destination code of the expense outflow, and a GPC code to indicate the government purpose of the expense.
4.13 The classification process is applied initially to all flows and stocks of new units and to new flows and stock items of existing units. The process may also be re-applied to existing items that have changed description from the previous period or have changed in value significantly and are suspected to have changed content.
INPUT OF DATA TO GFS PROCESSING SYSTEM
4.14 The next step in compiling the statistics is loading and editing the analysed data into the GFS processing system. Data are loaded by electronic processes or by manual intervention and are edited directly on the ABS GFS input database. The electronic file supplied by each Treasury contains accounting data for each unit and contains data item descriptions as they appear in source records, the data (values) for each item in each period, and the GFS classifications for each item.
4.15 The purposes of the input data base are to:
- store up-to-date unit-level data;
- serve as the source for the output data base.
INPUT EDITING
4.16 Input editing involves applying pre-specified edits to unit level data. The edits performed are unit edits, intra-sector edits and aggregate edits, each of which is described below. The process involves passing the unit data through editing programs, producing error reports, and making amendments to obtain a ‘clean’ data file.
EDITS ON UNITS
4.17 Three main types of unit edits are applied in the system: classification edits, account balance edits, and subtotalling edits.
4.18 Classification edits are edits designed to check the validity of the GFS classification codes assigned to flows and stocks. Four types of classification edits are applied:
- legality edits, which check that the unit and flows and stocks classification codes allocated actually exist in the classifications concerned;
- code combination edits, which check whether the combination of classification codes applied to each flow and stock item is valid within the GFS system;
- code existence edits, which check that where a given classification code has been allocated to a flow or stock item, codes from all of the relevant other classifications that are associated with that item have also been allocated;
- level of coding edits, which check that the prescribed minimum level of coding has been observed (see Chapter 5 for an explanation of the minimum level of coding).
4.19 Account balance edits are edits to check that the values for data items have been correctly entered, that data are not duplicated, and that data items entered into the system for each unit account for all items in that unit's source records.
4.20 As discussed previously, under the double-entry convention used in the system revenues, decreases in assets, and increase in liabilities and equity are treated as credits (Cr), and expenses, increases in assets, and decreases in liabilities and equity are treated as debits (Dr). Credits are stored in the system with a negative sign and debits with a positive sign. The account balance edit checks that the total of debits for a unit equals the total of credits.
4.21 To help locate account balance errors within a unit, data items are divided into balance groups for assets, liabilities and equity, revenues and expenses. The system checks that the accounting identity, Assets = Liabilities + Equity + Net Worth, is satisfied.
4.22 Subtotalling edits are used with account balance edits to pinpoint balancing errors within a unit. These edits are used whenever a set of data items should sum to a subtotal and where a set of subtotals should add to a control total.
INTRA-SECTOR EDITS
4.23 Intra-sector edits are performed in order to identify flow (and stock) imbalances, using the Source/Destination Code (SDC) assigned to most GFS items. The SDC identifies the source of the funds if a transaction is an operating revenue or a cash receipt, and the destination of the funds if the transaction is an operating expense or a cash payment. For Balance Sheet items the asset SDC identifies the sector in which the asset is held and the liability SDC identifies the sector to which the liability is owed.
4.24 Identifying and reconciling flow imbalances is necessary in order to achieve reasonably accurate consolidated results. However, not all flow imbalances can be resolved within GFS publication deadlines which means that the remaining imbalances contribute to the non-additivity of GFS measures across sectors and levels of government. A different approach is taken for other users of GFS. For example, because the national accounts and international bodies such as the IMF and the OECD require 'balanced' GFS output, adjustments are made to force both sides to align based on an accepted order of precedence, e.g. Commonwealth figures take precedence over lower levels of government, state figures take precedence over local etc.
AGGREGATE EDITS
4.25 Aggregate edits are applied after unit and intra-sector edits have been completed and resultant amendments made. These edits generally involve checking period to period changes in aggregates relating to the main GFS classifications.
4.26 The purpose of the edits is to identify any significant or unusual movements in important aggregates (e.g. expenses, net acquisition of non-financial assets, revenues, debt) so as to provide a check on the consistency of coding.
DATA AGGREGATION, DERIVATION AND CONSOLIDATION
4.27 When input editing has been completed, aggregation, derivation and consolidation processes are undertaken. During this phase, the unit information is no longer relevant and so is removed. The resulting data are classification and sector based.
4.28 These processes are summarised below:
- the aggregation of records with identical classification combinations;
- the derivation of items not collected, e.g. SDCs for liabilities - these are derived from the asset side for each instrument;
- consolidation, i.e. the elimination of flows within and between sectors;
- estimation for uncollected or missing data;
- the creation of a classification and sector-based output data store.
4.29 The aggregation step involves summing records with identical classifications within each of the output sectors (listed in Table 5.1). This step results in the generation of unique aggregated lines, i.e. there are no duplicates in the final data store.
4.30 Deriving special output data items involves creating, in unit records of general government and public non-financial corporations, those items required specifically for the Australian national accounts. Because no direct sources of data exist for these items, they are derived by applying selected ratios to the relevant aggregates. The ratios are obtained from external data (e.g. Commonwealth employment by state).
4.31 The consolidation process eliminates the flows and stock holdings that occur between units for each unique aggregate. It is the process whereby the two sides of the same transaction or stock holding are matched and eliminated to avoid double counting.
4.32 However, the system procedure used for consolidation is different from the logical process described above. Instead of matching and eliminating flows and stocks of individual units, the system omits from a given aggregate the flows and stocks that carry the source and destination codes (see paragraph 4.10) relevant to that aggregate. For example, in an aggregation relating to Commonwealth general government, all flows and stocks with a Commonwealth general government source or destination code would be omitted from the aggregate. This process has the same effect as matching and eliminating the flows and stocks of individual units.
4.33 Estimation is the process of generating data not collected and is relevant only for quarterly GFS where, due to time and cost constraints, some items are not collected and smaller units are not approached. At the beginning of the financial year forward estimates become available and these are used, together with other information, to estimate the missing data.
4.34 The creation of the output data store is the process of moving the disaggregated data from the unit-based input store to an aggregated and consolidated output store, formatted to enable the efficient production of GFS outputs.
OUTPUT EDITING
4.35 While unit and intra-sector edits (the input edits) check that (i) the classifications applied are legal, (ii) the accounts balance and (iii) flows between units are reconciled, these edits cannot establish that the correct values have been recorded. For this reason, another level of editing (output editing) is carried out prior to releasing the statistics. Output editing involves looking at the final results of the above processes to see if they are consistent with expectations given current government policies and economic conditions.
4.36 The first step in output editing involves examining trend, revision and relationship edits to identify and correct errors. GFS tables are then examined to compare data trends and movements in GFS aggregates and GFS bottom-line measures with data published in Budget documents and other public sector financial reports.
4.37 Significant variations in trend, identified in percentage and/or in dollar value terms, are the main triggers for suspecting errors in output. However, the type of transaction must be taken into account. For example, because of their volatility, large or unusual movements in capital expenditures might be less likely to indicate a possible error than movements of similar magnitude in current expenditures. Nevertheless, significant movements are investigated to determine their cause and validity. Investigation involves retrieval of the unit record data and, if necessary, raising a query with the authorities responsible for supplying the data.
4.38 Relationships between aggregates are also examined. For example, increased borrowings generally lead to increased interest payments in subsequent periods. Thus, if marked increases in borrowings are not followed by commensurate increases in interest expenses, both the borrowings and the interest data are investigated.
4.39 Output editing also aims to ensure that the statistics reflect the impact of changes in governments’ policies and overall trends in public sector finances. Current knowledge of changes in government policy, economic conditions and public sector finance issues is obtained from budget papers and press releases.
4.40 Where incorrect data are identified as a result of output editing, the input data are corrected and a revised output store created to ensure that both stores remain consistent at the aggregate level.
4.41 Before aggregate data can be published or released outside the ABS in any form, they must be checked to ensure that they do not disclose any information that is confidential under the provisions of the Census and Statistics Act 1905.
 Print Page
Print Page
 Print All
Print All