TECHNICAL NOTE SAMPLING VARIABILITY
ESTIMATION PROCEDURE
1. Estimates derived from the survey were obtained in two stages. In the first stage the effects of non-response were investigated by analysing the demographic composition of the Monthly Population Survey sample and response patterns to the Crime and Safety Survey after reminder action had been undertaken. This information was used to determine the appropriate adjustment procedure for non-response.
2. The second stage was a regression estimation procedure. This procedure ensured that the survey estimates for persons conformed to independent population totals, commonly referred to as 'benchmarks', rather than to the distribution of demographic characteristics among the survey respondents. These benchmarks consist of population estimates by age, sex and part of state. A similar procedure also ensured that household estimates conformed to independent estimates of households by number of adults, number of children in the household and part of state. Unlike the person benchmarks, these household benchmarks are actually estimates themselves and not strictly known population totals.
3. Since the 2006 Crime and Safety Survey, the weighting procedure has been refined to incorporate previously separate non-response adjustments and to improve the representation of survey error. To ensure this would not effect the time series, estimates from the 2006 Crime and Safety survey were re-calculated using the new method, and victimisation rates obtained via this method were compared with victimisation rates obtained using the previous method. No significant difference in victimisation rates across the two methods was found.
4. Since the 2004 Crime and Safety Survey, the process for producing household benchmarks has been refined. Whilst this process is still under review, it represents a significant improvement to the previous method and household benchmarks produced using the new method are considered sufficient quality for use in household survey estimation. In addition, measures of the variability in household benchmarks have been incorporated into household estimates for the first time. These changes may result in unexpected movements in total households (at some broad levels) due to revised benchmark methodology. A paper describing these issues in detail is currently being developed and will be released with catalogue number 3107.0.55.007.
RELIABILITY OF ESTIMATES
5. Estimates in this publication are subject to non-sampling and sampling errors.
Non-sampling errors
6. Non-sampling errors may arise as a result of errors in the reporting, recording or processing of the data and can occur even if there is a complete enumeration of the population. Non-sampling errors can be introduced through inadequacies in the questionnaire, non-response, inaccurate reporting by respondents, errors in the application of survey procedures, incorrect recording of answers and errors in data entry and processing.
7. It is difficult to measure the size of the non-sampling errors. The extent of these errors could vary considerably from survey to survey and from question to question. Every effort is made to minimise reporting error by the careful design of questionnaires, intensive training and supervision of staff, and efficient data processing procedures.
Sampling errors
8. Sampling errors are the errors which occur by chance because the data was obtained from a sample, rather than from the entire population.
ESTIMATES OF SAMPLING ERRORS
9. One measure of the variability of estimates which occurs as a result of surveying only a sample of the population is the standard error.
10. There are about 2 chances in 3 (67%) that a sample estimate will differ by less than one standard error from the number that would have been obtained if all dwellings had been included, and about 19 chances in 20 (95%) that the difference will be less than two standard errors.
11. The standard error (SE) can also be expressed as a percentage of the estimate. This is known as the relative standard error (RSE). The relative standard error is determined by dividing the standard error of an estimate SE(x) by the estimate x and expressing it as a percentage. That is - (where x is the estimate)
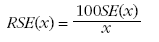
12. Space does not allow for the separate indication of the SEs and/or RSEs of all the estimates in this publication. However, RSEs for all of these estimates are available free-of-charge on the ABS web site <www.abs.gov.au>, released in spreadsheet format as an attachment to this publication, Crime and Safety, New South Wales, 2008 (cat. no. 4509.1).
13. An example of the calculation and use of standard errors for estimates of households follows. Table 1 shows that the estimated number of households in NSW that have been a victim of motor vehicle theft is 18,800. In the RSE spreadsheet table, the RSE for this estimate is shown to be 23.4%. The SE is -

14. Thus there are about 2 chances in 3 that the value that would have been obtained, had all dwellings been included in the survey, lies between 14,400 and 23,200. Similarly, there are about 19 chances in 20 that the value lies between 10,000 and 27,600.
15. Proportions and percentages formed from the ratio of two estimates are also subject to sampling error. This size of the error depends on the accuracy of both the numerator and the denominator. The formula for the relative standard error (RSE) of a proportion or percentage is -
![Equation: RSE (x/y) = Square root of [RSE(x)] suqared - [RSE(y)] squared](/ausstats/abs@.nsf/0/82dc6222d9fbd046ca256df20070348e/Body/0.38A4!OpenElement&FieldElemFormat=gif)
16. Only estimates with relative standard errors of 25% or less are considered sufficiently reliable for most purposes. However, estimates with a larger RSE have been included, preceded by * (RSE between 25% and 50%) or ** (RSE greater than 50%) to indicate that they are subject to high standard errors and should be used with caution.
NOTE ON CHANGE TO STANDARD ERRORS
17. Due to the change in sample size (see paragraph 6 of the Explanatory Notes), the relative standard errors of estimates for the 2008 Crime and Safety Survey have increased since the 2007 Crime and Safety Survey. For standard errors associated with previous cycles of the survey, see previous releases of this publication.
STATISTICAL SIGNIFICANCE TESTING
18. Where differences between data items have been noted in the Summary of Findings, they are statistically significant unless otherwise specified. In this publication a statistically significant difference is one where there are 19 chances in 20 that the difference noted reflects a true difference between population groups of interest rather than being the result of sampling variability.
19. In tables 1, 2, 3, 4, 6 and 9 of this publication, apparent changes in results between the 2008 survey and previous NSW Crime and Safety surveys have been tested to determine whether the changes are statistically significant. That is, to determine whether it is likely that the differences observed in sample estimates indicate real differences in the population. In these tables, cells which have not changed significantly over time are indicated. In other tables, which do not show the results of significance testing, RSEs should be taken into account when comparing estimates for different populations.
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All