|
|
WEIGHTING, BENCHMARKING, ESTIMATION AND STANDARDISATION
Weighting
1 Weighting is the process of adjusting results from a sample survey to infer results for the total population. To do this, a 'weight' is allocated to each sample unit. The weight is a value which indicates how many population units are represented by the sample unit.
2 The first step in calculating weights for the total sample of Indigenous persons in the 2001 National Health Survey (NHS) was to assign an initial weight. Initial weights were based on whether the respondent was selected in the main NHS or the supplementary Indigenous sample. A person's initial weight was calculated as the inverse of the probability of being selected in their respective sample. For example, if the probability of a person being selected in the supplementary sample was 1 in 600, then the person would have an initial weight of 600 (i.e. they represent 600 others).
Benchmarking
3 The initial weights were calibrated to align with independent estimates of the population of interest, referred to as 'benchmarks', in designated sex by age and area of usual residence categories. Weights calibrated against population benchmarks compensate for over- or under-enumeration of particular categories of persons and ensure that the survey estimates conform to the independently estimated distribution of the population by age, sex and area of usual residence, rather than to the distribution within the sample itself.
4 The Indigenous component of the 2001 NHS was benchmarked to the estimated Indigenous population at 30 June 2001 based on results from the 2001 Census of Population and Housing.
Estimation
5 Survey estimates of counts of persons are obtained by summing the weights of persons with the characteristic of interest. Estimates of non-person counts (e.g. days away from work, millilitres of alcohol consumed) are obtained by multiplying the characteristic of interest with the weight of the reporting person and aggregating.
Standardisation
6 Age standardisation techniques have been used to remove the effect of the differing age structures in the Indigenous and non-Indigenous populations for 2001, and over time. The age structure of the Indigenous population is considerably younger than that of the non-Indigenous population, and age is strongly related to many health measures. Therefore, estimates of prevalence which do not take account of age may be misleading. The age standardised estimate of prevalence is that which would have prevailed should the Indigenous and non-Indigenous populations have the standard age composition. The standard population used is the total Australian population at 30 June 2001 based on the 2001 Census of Population and Housing, adjusted for the scope of the survey.
7 The direct age standardisation method was used and the formula is as follows:
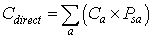
where Cdirect = the age standardised estimate of prevalence for the population of interest, a = the age categories that have been used in the age standardisation, ca = the estimate of prevalence for the population being standardised in age category a, and Psa = the proportion of the standard population in age category a. The age categories used in the standardisation were 5 year age groups to age 44, 45-54, and 55+ years of age.
RELIABILITY OF ESTIMATES
Non-sampling error
8 In addition to sampling error, survey estimates are subject to non-sampling errors. Sources of non-sampling error include:
- non-response, when people are unable or unwilling to provide the information being sought;
- errors in reporting by respondents, e.g. answers were based on memory, or because of misunderstanding or unwillingness of respondents to reveal all details;
- mistakes by interviewers when recording answers; and
- errors in the coding and processing of data.
9 Every effort is made to keep non-sampling errors in ABS surveys to a minimum by careful design and testing of questionnaires, training of interviewers, asking respondents to refer to records where appropriate, and extensive editing and quality control procedures at all stages of data processing.
Sampling error
10 Since the survey estimates are based on a sample, they are subject to sampling error. Sampling error is the difference between the published estimates, derived from a sample of persons, and the value that would have been produced if the entire population had been surveyed.
11 One measure of the likely difference is given by the Standard Error (SE), which indicates the extent to which an estimate might have varied by chance because a sample of the population was taken. There are about two chances in three that a sample estimate will differ by less than one SE from the figure that would have been obtained if the entire population had been included, and about 19 chances in 20 that the difference will be less than two SEs.
12 Another measure of the likely difference is the Relative Standard Error (RSE), which is obtained by expressing the SE as a percentage of the estimate. A table of SEs and RSEs for estimates of numbers of persons has been included in these Technical notes. These figures will not give a precise measure of the SE for a particular estimate but will provide an indication of its magnitude.
13 As can be seen from the SE table, the smaller the estimate the higher the RSE. Very small estimates are thus subject to such high RSEs as to detract seriously from their value for most uses. Estimates with a RSE of 25% to 50% are preceded by a single asterisk (e.g. *2.7) to indicate the estimate is subject to high RSEs and should be used with caution. Estimates with a RSE over 50% are preceded by a double asterisk ( e.g. **4.2) to indicate they are subject to very high sampling error and should be considered too unreliable for most purposes.
STANDARD ERRORS OF RATES AND PERCENTAGES
Comparisons of estimates
14 Published estimates may also be used to calculate the difference between two survey estimates (of number or percentages). Such an estimate is subject to sampling error. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x - y) may be calculated by the following formula:
SE (x - y) = sqrt [SE(x)]2 + [SE(y)]2
15 While the above formula will be exact only for differences between separate and uncorrelated (unrelated) characteristics of subpopulations, it is expected that it will provide a reasonable approximation for all differences likely to be of interest in this publication.
SIGNIFICANCE TESTING
16 Significance testing has been undertaken for the comparison of estimates included in table 1 (between the Indigenous and non-Indigenous populations) and table 2 (between Indigenous estimates for 1995 and 2001). The statistical significance test for any of the comparisons between estimates was performed to determine whether it is likely that there is a difference between the corresponding population characteristics. The standard error of the difference between two corresponding estimates (x and y) can be calculated using the formula in paragraph 14.
17 This standard error is then used to calculate the following test statistic:
|x-y|
SE(x-y)
18 If the value of this test statistic is greater than 1.96, then there are 19 chances in 20 that there is a real difference in the two populations with respect to that characteristic. Otherwise, it can not be stated with confidence that there is a real difference between the populations.
POPULATION TABLES
19 The estimates in this publication are presented as proportions. However, the populations presented in the following tables can be used to calculate the estimates as numbers.
T1: Population estimates by age and sex, Australia, 2001
 T2: Population estimates, Australia, 2001
T2: Population estimates, Australia, 2001
 STANDARD ERROR TABLES
20 The following table should be used for Indigenous persons for all variables. Where Indigenous estimates from the 2001 collection have been age standardised, the standard errors are, on average, between 10% and 30% higher than the corresponding standard error of unstandardised estimates. Therefore, an adjustment factor of approximately 1.2 should be applied to the estimated RSE of 2001 Indigenous age standardised estimates. Where Indigenous estimates from the 1995 collection have been age standardised, the RSE factors presented in T4 should be applied to the estimated RSE of the Indigenous age standardised estimates.
T3: Standard and Relative Standard Errors for 1995 and 2001 Indigenous estimates
STANDARD ERROR TABLES
20 The following table should be used for Indigenous persons for all variables. Where Indigenous estimates from the 2001 collection have been age standardised, the standard errors are, on average, between 10% and 30% higher than the corresponding standard error of unstandardised estimates. Therefore, an adjustment factor of approximately 1.2 should be applied to the estimated RSE of 2001 Indigenous age standardised estimates. Where Indigenous estimates from the 1995 collection have been age standardised, the RSE factors presented in T4 should be applied to the estimated RSE of the Indigenous age standardised estimates.
T3: Standard and Relative Standard Errors for 1995 and 2001 Indigenous estimates
|
1995 | 1995 | 1995 | 2001 | 2001 | 2001 |
Size of Estimate | Standard Error | Relative Standard Error | Size of Estimate | Standard Error | Relative Standard Error |
 | no. | % | | no. | % |
500 | 290 | 58.3 | 500 | 270 | 54.3 |
600 | 330 | 55.0 | 600 | 310 | 51.2 |
700 | 370 | 52.4 | 700 | 340 | 48.6 |
800 | 400 | 50.1 | 800 | 370 | 46.4 |
900 | 430 | 48.2 | 900 | 400 | 44.5 |
1 000 | 460 | 46.5 | 1 000 | 430 | 42.8 |
1 100 | 490 | 45.0 | 1 100 | 450 | 41.3 |
1 200 | 520 | 43.6 | 1 200 | 480 | 40.0 |
1 300 | 550 | 42.4 | 1 300 | 500 | 38.8 |
1 400 | 580 | 41.3 | 1 400 | 530 | 37.7 |
1 500 | 600 | 40.3 | 1 500 | 550 | 36.7 |
1 600 | 630 | 39.3 | 1 600 | 570 | 35.8 |
1 700 | 650 | 38.5 | 1 700 | 590 | 34.9 |
1 800 | 680 | 37.7 | 1 800 | 610 | 34.1 |
1 900 | 700 | 36.9 | 1 900 | 630 | 33.4 |
2 000 | 720 | 36.2 | 2 000 | 650 | 32.7 |
2 100 | 750 | 35.6 | 2 100 | 670 | 32.0 |
2 200 | 770 | 34.9 | 2 200 | 690 | 31.4 |
2 300 | 790 | 34.3 | 2 300 | 710 | 30.8 |
2 400 | 810 | 33.8 | 2 400 | 730 | 30.3 |
2 500 | 830 | 33.3 | 2 500 | 740 | 29.8 |
3 000 | 930 | 31.0 | 3 000 | 830 | 27.5 |
3 500 | 1 020 | 29.1 | 3 500 | 900 | 25.7 |
4 000 | 1 100 | 27.6 | 4 000 | 970 | 24.2 |
4 500 | 1 180 | 26.3 | 4 500 | 1 030 | 22.9 |
5 000 | 1 260 | 25.2 | 5 000 | 1 090 | 21.8 |
6 000 | 1 400 | 23.3 | 6 000 | 1 200 | 20.0 |
7 000 | 1530 | 21.8 | 7 000 | 1 300 | 18.6 |
8 000 | 1 650 | 20.6 | 8 000 | 1 390 | 17.4 |
9 000 | 1760 | 19.6 | 9 000 | 1 470 | 16.4 |
10 000 | 1 870 | 18.7 | 10 000 | 1 550 | 15.5 |
20 000 | 2 700 | 13.5 | 20 000 | 2 130 | 10.7 |
30 000 | 3 320 | 11.1 | 30 000 | 2 540 | 8.5 |
40 000 | 3 830 | 9.6 | 40 000 | 2 850 | 7.1 |
50 000 | 4 270 | 8.5 | 50 000 | 3 110 | 6.2 |
100 000 | 5 870 | 5.9 | 100 000 | 3 980 | 4.0 |
200 000 | 7 910 | 4.0 | 200 000 | 4 940 | 2.5 |
300 000 | 9 320 | 3.1 | 300 000 | 5 520 | 1.8 |
400 000 | 10 430 | 2.6 | 400 000 | 5 940 | 1.5 |
|
T4: Standard Error factors for age standardised 1995 Indigenous estimates
|
| Population | Factor |
| All persons | 1.261 |
| All persons aged 5 years and over | 1.233 |
| All persons aged 15 years and over | 1.189 |
| All persons aged 18 years and over | 1.181 |
|
21 The following table should be used for non-Indigenous persons for all variables except alcohol consumption (where T7 should be used). Although all 1995 estimates have been age standardised, the RSE factors for the non-Indigenous population are very close to 1 since this population is very similar in age structure to the standard population. The RSE factors for the non-Indigenous population can be found in T6.
T5: Standard and Relative Standard Errors for 1995 and 2001 non-Indigenous estimates
|
1995 | 1995 | 1995 | 2001 | 2001 | 2001 |
Size of Estimate | Standard Error | Relative Standard Error | Size of Estimate | Standard Error | Relative Standard Error |
| no. | % | | no. | % |
500 | 230 | 46.1 | 500 | 468 | 93.7 |
1 000 | 350 | 35.1 | 1 000 | 750 | 75.0 |
1 500 | 450 | 29.8 | 1 500 | 978 | 65.2 |
2 000 | 530 | 26.5 | 2 000 | 1 174 | 58.7 |
2 500 | 600 | 24.1 | 2 500 | 1 350 | 54.0 |
3 000 | 670 | 22.3 | 3 000 | 1 512 | 50.4 |
3 500 | 730 | 20.9 | 3 500 | 1 659 | 47.4 |
4 000 | 790 | 19.8 | 4 000 | 1 800 | 45.0 |
4 500 | 850 | 18.8 | 4 500 | 1 930 | 42.9 |
5 000 | 900 | 17.9 | 5 000 | 2 055 | 41.1 |
6 000 | 990 | 16.6 | 6 000 | 2 286 | 38.1 |
8 000 | 1 170 | 14.6 | 8 000 | 2 696 | 33.7 |
10 000 | 1 320 | 13.2 | 10 000 | 3 060 | 30.6 |
20 000 | 1 920 | 9.6 | 20 000 | 4 440 | 22.2 |
30 000 | 2 380 | 7.9 | 30 000 | 5 490 | 18.3 |
40 000 | 2 770 | 6.9 | 40 000 | 6 320 | 15.8 |
50 000 | 3 100 | 6.2 | 50 000 | 7 050 | 14.1 |
100 000 | 4 400 | 4.4 | 100 000 | 9 700 | 9.7 |
200 000 | 6 190 | 3.1 | 200 000 | 13 200 | 6.6 |
300 000 | 7 510 | 2.5 | 300 000 | 15 600 | 5.2 |
400 000 | 8 600 | 2.1 | 400 000 | 17 600 | 4.4 |
500 000 | 9 540 | 1.9 | 500 000 | 19 000 | 3.8 |
1 000 000 | 13 070 | 1.3 | 1 000 000 | 24 000 | 2.4 |
2 000 000 | 17 720 | 0.9 | 2 000 000 | 30 000 | 1.5 |
5 000 000 | 26 070 | 0.5 | 5 000 000 | 40 000 | 0.8 |
10 000 000 | 34 480 | 0.3 | 10 000 000 | 50 000 | 0.5 |
20 000 000 | 45 130 | 0.2 | 20 000 000 | 60 000 | 0.3 |
|
T6 Standard Error factors for age standardised 1995 non–Indigenous estimates
|
| Population | Factor |
| All persons | 1.002 |
| All persons aged 5 years and over | 1.002 |
| All persons aged 15 years and over | 1.003 |
| All persons aged 18 years and over | 1.003 |
|
22 For the 1995 non-Indigenous population, a different set of SEs exists for the tables relating to alcohol consumption. This is because the questions on alcohol consumption were only administered to half the non-Indigenous sample and weightings were calculated differently as a result.
T7: Standard and Relative Standard Errors for 1995 non-Indigenous estimates of alcohol consumption
|
1995 | 1995 | 1995 |
Size of Estimate | Standard Error | Relative Standard Error |
| no. | % |
100 | 470 | 472.1 |
200 | 640 | 320.6 |
300 | 770 | 255.1 |
400 | 870 | 216.7 |
500 | 950 | 190.9 |
600 | 1 030 | 172.0 |
700 | 1 100 | 157.5 |
800 | 1 170 | 145.8 |
900 | 1 230 | 136.3 |
1 000 | 1 280 | 128.3 |
1 100 | 1 340 | 121.4 |
1 200 | 1 390 | 115.4 |
1 300 | 1 430 | 110.2 |
1 400 | 1 480 | 105.6 |
1 500 | 1 520 | 101.4 |
1 600 | 1 560 | 97.7 |
1 700 | 1 600 | 94.3 |
1 800 | 1 640 | 91.2 |
1 900 | 1 680 | 88.4 |
2 000 | 1 720 | 85.8 |
2 100 | 1 750 | 83.4 |
2 200 | 1 790 | 81.2 |
2 300 | 1 820 | 79.1 |
2 400 | 1 850 | 77.1 |
2 500 | 1 880 | 75.3 |
3 000 | 2 030 | 67.7 |
3 500 | 2 160 | 61.8 |
4 000 | 2 290 | 57.1 |
4 500 | 2 400 | 53.3 |
5 000 | 2 500 | 50.1 |
6 000 | 2 700 | 44.9 |
8 000 | 3 030 | 37.9 |
10 000 | 3 320 | 33.2 |
20 000 | 4 370 | 21.8 |
30 000 | 5 120 | 17.1 |
40 000 | 5 730 | 14.3 |
50 000 | 6 250 | 12.5 |
100 000 | 8 150 | 8.2 |
200 000 | 10 590 | 5.3 |
300 000 | 12 310 | 4.1 |
400 000 | 13 680 | 3.4 |
500 000 | 14 850 | 3.0 |
1 000 000 | 19 080 | 1.9 |
2 000 000 | 24 400 | 1.2 |
5 000 000 | 33 550 | 0.7 |
10 000 000 | 42 470 | 0.4 |
20 000 000 | 53 520 | 0.3 |
|
|
 Print Page
Print Page
 Print All
Print All