TECHNICAL NOTE DATA QUALITY
RELIABILITY OF ESTIMATES
1 Since the estimates in this publication are based on information obtained from occupants of a sample of dwellings, they are subject to sampling variability. That is, they may differ from those estimates that would have been produced if all dwellings had been included in the survey. One measure of the likely difference is given by the standard error (SE), which indicates the extent to which an estimate might have varied by chance due to only a sample of dwellings being included. There are about two chances in three (67%) that a sample estimate will differ by less than one SE from the number that would have been obtained if all dwellings had been included, and about 19 chances in 20 (95%) that the difference will be less than two SEs. Another measure of the likely difference is the relative standard error (RSE), which is obtained by expressing the SE as a percentage of the estimate.
2 In general, the size of the SE increases as the size of the estimate increases. Conversely, the RSE decreases as the size of the estimate increases. Very small estimates are thus subject to such high RSEs that their value for most practical purposes is unreliable. In this publication, only estimates with RSEs of 25% or less are considered reliable for most purposes. Estimates with RSEs greater than 25% but less than or equal to 50% are preceded by an asterisk (e.g.*2.2) to indicate they are subject to high SEs and should be used with caution. Estimates with RSEs of greater than 50%, preceded by a double asterisk (e.g.**1.5), are considered too unreliable for general use and should only be used to aggregate with other estimates to provide derived estimates with RSEs of 25% or less.
3 The imprecision due to sampling variability, which is measured by the SE, should not be confused with inaccuracies that may occur because of imperfections in reporting by respondents and recording by interviewers, and errors made in coding and processing data. Inaccuracies of this kind are referred to as non-sampling error, and they may occur in any enumeration, whether it be a full count or a sample. Every effort is made to minimise non-sampling error by careful design of questionnaires, intensive training and supervision of interviewers, and efficient operating procedures.
4 Due to space limitations, it is impractical to print the SE of each estimate in this publication. A table of SEs and RSEs is provided at the end of this Technical Note to enable readers to determine the SE for an estimate from the size of that estimate. These figures will not give a precise measure of the SE for a particular estimate but will provide an indication of its magnitude.
CALCULATION OF STANDARD ERROR
Standard error of an estimate
5 An example of the calculation and the use of SEs in relation to estimates of persons is as follows. Consider the estimate for Australia of persons aged 25-34 years who have been a victim of assault within the last 12 months, which is 187,000. Since this estimate is between 100,000 and 200,000 in the SE table for person estimates, the SE for Australia will lie between 7,221 and 9,736 and can be approximated by interpolation using the following general formula:
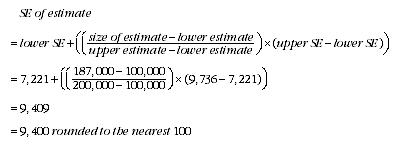
6 Therefore, there are about two chances in three that the value that would have been produced if all dwellings had been included in the survey will fall within the range 177,600 to 196,400 and about 19 chances in 20 that the value will fall within the range 168,200 to 205,800. This example is illustrated in the diagram below.
RSES OF COMPARATIVE ESTIMATES
Proportions and percentages
7 Proportions and percentages formed from the ratio of two estimates are also subject to sampling error. The size of the error depends on the accuracy of both the numerator and the denominator. For proportions where the denominator is an estimate of the number of persons in a group and the numerator is the number of persons in a sub-group of the denominator group, the formula to approximate the RSE is:
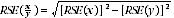
8 Considering the example above, the 187,000 persons aged 25-34 years who had been a victim of assault within the last 12 months represent 24.3% of the 770,600 persons who were victims of assault in the last 12 months. The SE of 770,600 may be calculated by interpolation as 16,400. To convert this to a RSE we express the SE as a percentage of the estimate, or 16,400/770,600=2.1%. The SE for 187,000 was calculated previously as 9,400 which converted to a RSE is 9,400/187,000=5.0%. Applying the above formula, the RSE of the proportion is
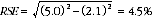
9 Therefore, the SE for the proportion of victims of assault aged 25-34 years in the last 12 months is 1.1 percentage points (=(24.3/100)×4.5). Therefore, there are about two chances in three that the proportion of victims of assault in the last 12 months who were persons aged 25-34 years is between 23.2% and 25.4% and 19 chances in 20 that the proportion is within the range 22.1% to 26.5%.
Differences between estimates
10 The difference between two survey estimates is itself an estimate and is therefore subject to sampling variability. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
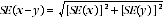
11 While this formula will only be exact for differences between separate and uncorrelated characteristics or subpopulations, it is expected to provide a good approximation for all differences likely to be of interest in this publication.
STATISTICAL SIGNIFICANCE TESTING
12 Where differences between data items have been noted in the Summary of Findings, they are statistically significant unless otherwise specified. In this publication a statistically significant difference is one where there are 19 chances in 20 that the difference noted reflects a true difference between population groups of interest rather than being the result of sampling variability.
13 Statistical significance testing has also been undertaken for the comparison of estimates between 2005, 2002 and 1998, included in tables 1, 2, 6 and 15. The statistical significance test for these comparisons was performed to determine whether it is likely that there is a difference between the corresponding population characteristics. The standard error of the difference between two corresponding estimates (x and y) can be calculated using the formula in paragraph 10. This standard error is used to calculate the following test statistic:
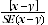
14 If the value of the test statistic is greater than 1.96 then we may say there is good evidence of a real difference in the two populations with respect to that characteristic. Otherwise, it cannot be stated with confidence that there is a real difference between the populations. Tables 1, 2, 6 and 15 are annotated to indicate whether the differences between estimates which have been compared are statistically significant. In other tables, which do not show the results of significance testing, users should take account of RSEs when comparing estimates for different populations.
T1 STANDARD ERROR OF ESTIMATES |
|  |
| STANDARD ERROR | RELATIVE STANDARD ERROR | |
| NSW | VIC | QLD | SA | WA | TAS | NT | ACT | Aust. | Aust. | |
| Size of estimate | no. | no. | no. | no. | no. | no. | no. | no. | no. | % | |
| |
| 500 | 505 | 536 | 469 | 385 | 361 | 265 | 312 | 247 | 440 | 92.2 | |
| 600 | 567 | 588 | 520 | 429 | 402 | 292 | 347 | 272 | 492 | 84.9 | |
| 700 | 624 | 636 | 567 | 470 | 441 | 317 | 379 | 294 | 540 | 79.1 | |
| 800 | 678 | 680 | 611 | 507 | 476 | 339 | 408 | 315 | 585 | 74.4 | |
| 900 | 729 | 721 | 653 | 543 | 510 | 361 | 435 | 334 | 628 | 70.4 | |
| 1,000 | 777 | 760 | 692 | 576 | 542 | 380 | 459 | 353 | 668 | 67.0 | |
| 1,100 | 823 | 796 | 729 | 608 | 572 | 399 | 482 | 369 | 707 | 64.1 | |
| 1,200 | 867 | 831 | 764 | 638 | 601 | 416 | 504 | 386 | 744 | 61.6 | |
| 1,300 | 910 | 865 | 798 | 667 | 629 | 433 | 524 | 401 | 779 | 59.3 | |
| 1,400 | 951 | 897 | 831 | 694 | 655 | 449 | 543 | 415 | 814 | 57.2 | |
| 1,500 | 990 | 928 | 862 | 721 | 681 | 464 | 561 | 429 | 847 | 55.4 | |
| 1,600 | 1 029 | 957 | 893 | 746 | 706 | 478 | 578 | 442 | 879 | 53.7 | |
| 1,700 | 1 066 | 986 | 922 | 771 | 729 | 492 | 595 | 455 | 910 | 52.2 | |
| 1,800 | 1 102 | 1 014 | 950 | 795 | 753 | 505 | 610 | 468 | 940 | 50.8 | |
| 1,900 | 1 137 | 1 040 | 978 | 818 | 775 | 518 | 625 | 479 | 970 | 49.5 | |
| 2,000 | 1 171 | 1 067 | 1 005 | 840 | 797 | 531 | 639 | 491 | 999 | 48.3 | |
| 2,100 | 1 205 | 1 092 | 1 031 | 862 | 818 | 543 | 653 | 502 | 1 027 | 47.2 | |
| 2,200 | 1 237 | 1 117 | 1 056 | 883 | 839 | 554 | 666 | 513 | 1 054 | 46.2 | |
| 2,300 | 1 269 | 1 141 | 1 081 | 904 | 859 | 565 | 679 | 523 | 1 081 | 45.2 | |
| 2,400 | 1 300 | 1 164 | 1 105 | 924 | 879 | 576 | 691 | 533 | 1 107 | 44.3 | |
| 2,500 | 1 330 | 1 187 | 1 129 | 943 | 898 | 587 | 703 | 543 | 1 133 | 43.4 | |
| 3,000 | 1 474 | 1 295 | 1 240 | 1 035 | 989 | 636 | 757 | 589 | 1 255 | 39.7 | |
| 3,500 | 1 606 | 1 393 | 1 341 | 1 117 | 1 071 | 680 | 803 | 630 | 1 366 | 36.8 | |
| 4,000 | 1 728 | 1 484 | 1 434 | 1 193 | 1 147 | 720 | 844 | 667 | 1 470 | 34.5 | |
| 4,500 | 1 842 | 1 568 | 1 521 | 1 262 | 1 218 | 756 | 880 | 701 | 1 567 | 32.6 | |
| 5,000 | 1 949 | 1 647 | 1 603 | 1 327 | 1 284 | 790 | 912 | 732 | 1 659 | 30.9 | |
| 6,000 | 2 148 | 1 792 | 1 753 | 1 445 | 1 405 | 850 | 968 | 788 | 1 830 | 28.2 | |
| 8,000 | 2 495 | 2 044 | 2 015 | 1 647 | 1 616 | 950 | 1 055 | 883 | 2 131 | 24.4 | |
| 10,000 | 2 796 | 2 262 | 2 239 | 1 817 | 1 796 | 1 033 | 1 120 | 961 | 2 393 | 21.8 | |
| 20,000 | 3 926 | 3 080 | 3 076 | 2 420 | 2 459 | 1 313 | 1 303 | 1 232 | 3 397 | 15.3 | |
| 30,000 | 4 741 | 3 673 | 3 676 | 2 826 | 2 926 | 1 492 | 1 389 | 1 407 | 4 141 | 12.4 | |
| 40,000 | 5 395 | 4 154 | 4 157 | 3 137 | 3 295 | 1 624 | 1 436 | 1 539 | 4 749 | 10.6 | |
| 50,000 | 5 950 | 4 565 | 4 563 | 3 390 | 3 604 | 1 729 | 1 465 | 1 645 | 5 273 | 9.4 | |
| 100,000 | 7 950 | 6 082 | 6 031 | 4 239 | 4 693 | 2 061 | 1 503 | 1 988 | 7 221 | 6.5 | |
| 200,000 | 10 399 | 8 029 | 7 840 | 5 157 | 5 980 | 2 389 | 1 461 | 2 343 | 9 736 | 4.4 | |
| 300,000 | 12 048 | 9 404 | 9 069 | 5 711 | 6 823 | 2 571 | | 2 550 | 11 513 | 3.5 | |
| 400,000 | 13 315 | 10 501 | 10 022 | 6 105 | 7 458 | 2 693 | . . | 2 694 | 12 926 | 3.0 | |
| 500,000 | 14 352 | 11 426 | 10 809 | 6 409 | 7 971 | 2 782 | . . | . . | 14 113 | 2.6 | |
| 1,000,000 | 17 866 | 14 762 | 13 517 | 7 319 | 9 662 | . . | . . | . . | 18 356 | 1.7 | |
| 2,000,000 | 21 770 | 18 897 | 16 625 | 8 133 | 11 461 | . . | . . | . . | 23 505 | 1.1 | |
| 5,000,000 | 27 359 | 25 821 | . . | . . | . . | . . | . . | . . | 31 825 | 0.7 | |
| 10,000,000 | . . | . . | . . | . . | . . | . . | . . | . . | 39 310 | 0.4 | |
| 15,000,000 | . . | . . | . . | . . | . . | . . | . . | . . | 44 160 | 0.3 | |
| |
| . . not applicable |
 Print Page
Print Page
 Print All
Print All