TECHNICAL NOTE SAMPLING ERROR
RELIABILITY OF ESTIMATES
1 As the estimates in this release are based on information relating to a sample of employers and employees, rather than a full enumeration, they are subject to sampling variability. That is, they may differ from the estimates that would have been produced if the information had been obtained from all employers and all employees. The difference, called sampling error, should not be confused with inaccuracy that may occur because of imperfections in reporting by respondents or in processing by the ABS. Such inaccuracy is referred to as non-sampling error and may occur in any enumeration whether it be a full count or a sample. Efforts have been made to reduce non-sampling error by careful design of questionnaires, detailed checking of returns and quality control of processing.
2 The sampling error associated with any estimate can be estimated from the sample results. One measure of sampling error is given by the standard error, which indicates the degree to which an estimate may vary from the value that would have been obtained from a full enumeration (the ‘true value'). There are about two chances in three that a sample estimate differs from the true value by less than one standard error, and about nineteen chances in twenty that the difference will be less than two standard errors. Standard errors are available in the Excel spreadsheet available from the Downloads tab of this release.
3 An example of the use of a standard error is as follows. If the estimated average weekly total cash earnings for all employees paid by collective agreement is $1,214.00, with a standard error of $19.70, there would be about two chances in three that a full enumeration would have given an estimate in the range $1,194.30 to $1,233.70 and about nineteen chances in twenty that it would be in the range $1,174.60 to $1,253.40.
4 The difference between two survey estimates is also an estimate and it is therefore subject to sampling variability. The standard error on the difference between two survey estimates in the one time period (i.e. x-y) can be calculated using the following formula:
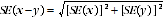
5 The formula above will overestimate the standard error where there is a positive correlation between two estimates (e.g. average weekly earnings for male and female school teachers). While this formula will only be accurate where there is no correlation between two estimates (e.g. estimates from different states), it is expected to provide a reasonable approximation of the standard error for the difference between two survey estimates.
6 The estimated average weekly total cash earnings for all male employees is $1,429.80, with a standard error of $14.50. For all female employees the estimated average weekly total cash earnings is $940.20 with a standard error of $8.90. Thus the difference between the estimate of male and female earnings is $489.60. The estimate of the standard error of the difference between the average weekly total cash earnings employees of males and females is:
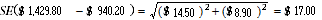
7 There are about two chances in three that the true figure for the difference between average weekly total cash earnings for males and females lies in the range $472.60 to $506.60 and about nineteen chances in twenty that the figure is in the range $455.60 to $523.60.
8 The formula above can be used to estimate the standard error on a difference between estimated averages in two different years. (The movement standard error will be approximately 1.4 times the standard error on the level estimate, if the standard errors on the two level estimates are similar).
9 Another measure of the sampling error is the relative standard error, which is obtained by expressing the standard error as a percentage of the estimate.
10 An asterisk appears against an estimate in this release where the sampling variability is considered high. For the tables in this release, estimates with relative standard errors above 25% have been labelled with a cell comment.
11 Standard errors can be used to construct confidence intervals around the estimated proportions. There are about two chances in three that the 'true' value is within the interval that ranges from the sample estimate minus one standard error (estimate - 1xSE) to the sample estimate plus one standard error (estimate + 1xSE). There are approximately 19 chances in 20 that the 'true' value lies within the interval from the estimate minus two standard errors (estimate - 2xSE) to the estimate plus two standard errors (estimate + 2xSE).
12 The above rule gives a symmetric confidence interval that is reasonably accurate when the estimated proportion is not too near 0.00 or 1.00. Where the estimated proportion is close to 0.00 or 1.00 it would be more accurate to use a confidence interval that was not symmetric around the sample estimate. If an estimate is close to 1.00, then the upper boundary of the confidence interval should be closer to the sample estimate than suggested above, while the lower boundary should be further from the sample estimate. Similarly, if an estimate is close to 0.00, then the lower boundary of the confidence interval should be closer to the sample estimate than suggested above, while the upper boundary should be further from the sample estimate. In particular, the symmetric confidence interval could include values that are not between 0.00 and 1.00. In such a case a good rule of thumb is to use a confidence interval of the same size as the symmetric one, but with the lower (or upper) boundary set to 0.00 (or 1.00).
13 Each data cube contains estimates of standard errors from which confidence intervals may be constructed.
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All