RELIABILITY OF ESTIMATES
The estimates provided in this publication are subject to two types of error, non-sampling and sampling error. These are discussed below.
Comparisons between estimates from surveys conducted in different periods, for example, comparison of 2005-06 SIH estimates with 2003-04 SIH estimates, are also subject to the impact of any changes made to the way the survey is conducted. See part 4 'Changes from previous surveys'.
Non-sampling error
Non-sampling error can occur in any collection, whether the estimates are derived from a sample or from a complete collection such as a census. Sources of non-sampling error include non-response, errors in reporting by respondents or recording of answers by interviewers and errors in coding and processing the data.
Non-sampling errors are difficult to quantify in any collection. However, every effort is made to reduce non-sampling error to a minimum by careful design and testing of the questionnaire, training of interviewers and data entry staff and extensive editing and quality control procedures at all stages of data processing.
One of the main sources of non-sampling error is non-response by persons selected in the survey. Non-response occurs when people cannot or will not cooperate or cannot be contacted. Non-response can affect the reliability of results and can introduce a bias. The magnitude of any bias depends upon the level of non-response and the extent of the difference between the characteristics of those people who responded to the survey and those who did not.
The following methods were adopted to reduce the level and impact of non-response:
- face-to-face interviews with respondents
- the use of interviewers who could speak languages other than English, where necessary
- follow-up of respondents if there was initially no response
- imputation of missing values
- ensuring that the weighted data is representative of the population (in terms of demographic characteristics) by aligning the estimates with population benchmarks.
Sampling error
The estimates are based on information obtained from the occupants of samples of dwellings. Therefore, the estimates are subject to sampling variability and may differ from the figures that would have been produced if information had been collected for all dwellings. One measure of the likely difference is given by the standard error (SE), which indicates the extent to which an estimate might have varied because only a sample of dwellings was included. There are about two chances in three that the sample estimate will differ by less than one SE from the figure that would have been obtained if all dwellings had been included, and about 19 chances in 20 that the difference will be less than two SEs. Another measure of the likely difference is the relative standard error (RSE), which is obtained by expressing the SE as a percentage of the estimate.
For estimates of population sizes, the size of the SE generally increases with the level of the estimate, so that the larger the estimate the larger the SE. However, the larger the sampling estimate the smaller the SE in percentage terms (RSE). Thus, larger sample estimates will be relatively more reliable than smaller estimates.
Estimates with RSEs of 25% or more are not considered reliable for most purposes. Estimates with RSEs greater than 25% but less than or equal to 50% are annotated by an asterisk to indicate they are subject to high SEs and should be used with caution. Estimates with RSEs of greater than 50%, annotated by a double asterisk, are considered too unreliable for general use and should only be used to aggregate with other estimates to provide derived estimates with RSEs of 25% or less.
Estimates of RSEs are provided on the ABS web site for all tables included in the published output from the SIH (see Part 3 'Data availability'). The RSEs have been derived using the group jackknife method. If needed, SEs can be calculated using the estimates and RSEs.
RSEs of comparative estimates
Proportions and percentages, which are formed from the ratio of two estimates, are also subject to sampling errors. The size of the error depends on the accuracy of both the numerator and the denominator. For proportions where the denominator is an estimate of the number of households in a grouping and the numerator is the number of households in a sub-group of the denominator group, the formula for the RSE is given by:
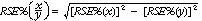
The difference between survey estimates is also subject to sampling variability. An approximate SE of the difference between two estimates (x-y) may be calculated by the formula:
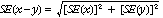
This approximation can generally be used whenever the estimates come from different samples, such as two estimates from different years or two estimates for two non-intersecting subpopulations in the one year. If the estimates come from two populations, one of which is a subpopulation of the other, the standard error is likely to be lower than that derived from this approximation, but there is no straightforward way of estimating how much lower.
Significance testing
Statistical significance testing can be undertaken to determine whether it is likely that there is a difference between two estimates from different samples. The standard error for the difference between two estimates can be calculated using the formula in the paragraph above. The standard error is used to calculate the following test statistic:

If the value of this test statistic is greater than 1.96 then there are 19 chances in 20 that there is a real difference in the two populations with respect to that characteristic. Otherwise, it cannot be stated with confidence that there is a real difference between the populations.
 Print Page
Print Page
 Print All
Print All