TECHNICAL NOTE
RELIABILITY OF THE ESTIMATES
1 As the estimates in this publication are based on information obtained from a sample of persons, they are subject to sampling variability. That is, the estimates may differ from those that would have been produced had all persons been included in the survey.
2 One measure of the likely difference is given by the standard error (SE), which indicates the extent to which an estimate might have varied by chance because only a sample of persons was included. There are about two chances in three (67%) that a sample estimate will differ by less than one SE from the number that would have been obtained if all persons had been surveyed, and about 19 chances in 20 (95%) that the difference will be less than two SEs.
3 Another measure of the likely difference is the relative standard error (RSE), which is obtained by expressing the SE as a percentage of the estimate.

4 RSEs for all estimates have been calculated using the Jackknife method of variance estimation. This involves the calculation of 30 'replicate' estimates based on 30 different subsamples of the obtained sample. The variability of estimates obtained from these subsamples is used to estimate the sample variability surrounding the estimate.
5 The Excel spreadsheets (in Downloads) contain all the tables produced for this release and the calculated RSEs for each of the estimates.
6 Only estimates (numbers or percentages) with RSEs less than 25% are considered sufficiently reliable for most analytical purposes. However, estimates with larger RSEs have been included. Estimates with an RSE in the range 25% to 50% should be used with caution while estimates with RSEs greater than 50% are considered too unreliable for general use. All cells in the Excel spreadsheets with RSEs greater than 25% contain a comment indicating the size of the RSE. These cells can be identified by a red indicator in the corner of the cell. The comment appears when the mouse pointer hovers over the cell.
CALCULATION OF STANDARD ERROR
7 Standard errors can be calculated using the estimates (counts or percentages) and the corresponding RSEs. For example, Table 1 shows that the estimated number of persons who were victims of physical assault in the last 12 months was 539,800. The RSE corresponding to this estimate is 4.5%. The SE (rounded to the nearest 100) is calculated by:
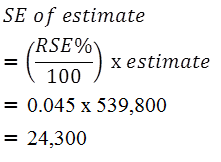
8 Therefore, there are about two chances in three that the value that would have been produced if all dwellings had been included in the survey will fall within the range 461,700 to 511,300 and about 19 chances in 20 that the value will fall within the range 436,900 to 536,100. This example is illustrated in the diagram below:

PROPORTIONS AND PERCENTAGES
9 Proportions and percentages formed from the ratio of two estimates are also subject to sampling errors. The size of the error depends on the accuracy of both the numerator and the denominator. A formula to approximate the RSE of a proportion is given below. This formula is only valid when x is a subset of y:
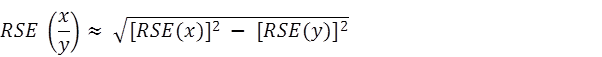
10 As an example, using estimates from Table 1, 243,700 victims of physical assault experienced one incident of this type of crime, representing 45.1% of all victims of physical assault. The RSE for the number of physical assault victims experiencing one incident is 6.5% and the RSE for the number of victims of physical assault is 4.5%. Applying the above formula, the RSE of the proportion is:
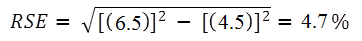
11 Therefore, the SE for physical assault victims who experienced one incident, as a proportion of all physical assault victims, is 2.1 percentage points (=4.7×(45.1/100)). Hence, there are about two chances in three that the proportion of victims who only experienced one incident of physical assault is between 52.0% and 56.2% and 19 chances in 20 that the proportion is within the range 49.9% to 58.3%.
DIFFERENCES
12 The difference between two survey estimates (counts or percentages) can also be calculated from published estimates. Such an estimate is also subject to sampling error. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
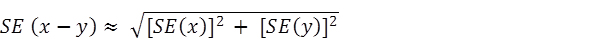
13 While this formula will only be exact for differences between separate and uncorrelated characteristics or sub populations, it provides a good approximation for the differences likely to be of interest in this publication.
SIGNIFICANCE TESTING
14 A statistical significance test for a comparison between estimates can be performed to determine whether it is likely that there is a difference between the corresponding population characteristics. The standard error of the difference between two corresponding estimates (x and y) can be calculated using the formula shown above in the Differences section. This standard error is then used to calculate the following test statistic:

15 If the value of this test statistic is greater than 1.96 then there is evidence, with a 95% level of confidence, of a statistically significant difference in the two populations with respect to that characteristic. Otherwise, it cannot be stated with confidence that there is a real difference between the populations with respect to that characteristic.
16 Tables which show rates from 2008–09, 2009–10, 2010–11 and 2011–12 have been tested to determine whether changes over time are statistically significant. Significant differences have been annotated. In all other tables which do not show the results of significance testing, users should take account of RSEs when comparing estimates for different populations.
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All