INTEGRATION METHODOLOGY
The LEED Foundation Projects Integrated Dataset was created through a two stage process. The first stage involved linking the three PIT subsets together, and the second stage involved integrating the PIT dataset with the EABLD extract.
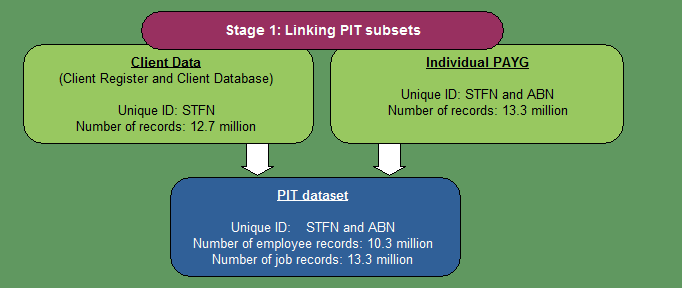
STAGE 1: LINKING PIT DATASETS
The first stage of data integration involved linking the cleaned PIT subsets (Client Register, Client Dataset and Individual PAYG Dataset) together using STFN as the linking key. Once these person level and job level data were linked, it was possible to identify persons who neither reported earnings on an ITR nor had an Individual PAYG summary during the 2011-12 financial year. These persons were deemed not to be employees in 2011-12 (out of scope) and were removed.
The resulting PIT dataset contains 10,334,718 employee records and 13,316,438 job records. Of all employee records, 94.4% have a corresponding job record. The 5.6% of employees who did not have a corresponding job record represent those employees who did not have an Individual PAYG summary for the reference period (such as persons who worked for cash in hand) but who still lodged an ITR and reported earnings. Of the job records, less than 0.001% did not have a corresponding employee record. As the linking variable is encrypted, it is impossible to determine whether any of the unlinked job records failed to link due to an error in the linking key, however the low number of unlinked jobs suggests that errors are minimal.
Diagram 2: Linking PIT datasets
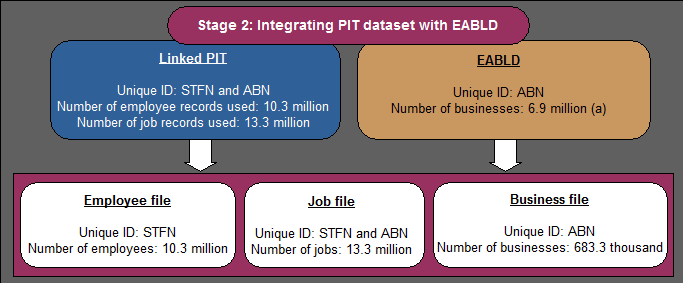
STAGE 2: INTEGRATING PIT DATASET WITH EABLD
The second stage of data integration involved integrating the PIT dataset with the EABLD extract using ABN as the linking key. At this stage of the integration process, it was possible to identify businesses which did not have any PIT records linked to them. These businesses were deemed to be non-employing businesses in 2011-12 (out of scope) and were removed. As a result of this process, 683,331 business records were identified as employing businesses in the 2011-12 financial year.
Integrating the PIT dataset with the EABLD extract involved different processes for businesses in the non-profiled and profiled populations.
Non-profiled population
The PIT dataset was linked to non-profiled businesses on the EABLD extract using ABN as the linking key. This resulted in approximately 51% of jobs and 51% of employees being linked to a business in the non-profiled population.
Profiled population
Approximately 49% of jobs and 53% of employees were linked to a business in the profiled population. The EABLD extract contains information about profiled businesses at the TAU level. Because a profiled business may contain multiple TAUs, and because each ABN linked to this business can operate (either wholly or partially) in a selection of these TAUs, it was not possible to link ABNs of jobs directly to the TAUs of the businesses.
Rather than attempt to present the full complexity of businesses, it was decided to provide a single set of business information per job to allow for the effective calculation of employee and job statistics. In order to do this, the following
ABN to TAU mapping process was employed to link each ABN to a single TAU within the EG. Linking entire ABNs to single TAUs allowed cohorts of employees working in the same business to remain linked together for microdata analysis. Other approaches such as linking individual jobs to TAUs may provide alternative means to perform this linking in future.
ABN to TAU mapping
For each ABN on the PIT dataset which linked to a business in the profiled population (i.e. an EG, represented by one or more TAUs on the EABLD extract), the ABN to TAU mapping process provided a link from an ABN to a single TAU. Each job associated with that ABN was linked to that TAU. This process is based on information collected by the ABS as part of the ABSBR business profiling.
Of the 56,549 ABNs in the profiled population, 51% linked to a single TAU and further mapping was not required.
Of the remaining 49% of ABNs, approximately 0.5% could link to multiple TAUs, while the other 48.5% may link to one or multiple TAUs. Information from the ABS business profiling process in 2014 indicates that the overwhelming majority of ABNs (over 95%) in the profiled population map to a single TAU, but this information was not available for 2011-12.
A two-step process was developed to assign each remaining ABN to a single TAU. The first step was to calculate allocation weights (
aw) between 0 and 99 for each potential combination of ABN and TAU. Each
aw represents the probability that an ABN links to a particular TAU within the EG. The probabilities are based on the distribution of employees and income within the EG.
For example an ABN which may link to two TAUs (on a 70:30 probability ratio) would be represented by two ABN-TAU pairs:
- ABN:TAU 1, aw = 70
- ABN:TAU 2, aw = 30
The second step was to assign each ABN to a single TAU in the EG. This was done by selecting, for each ABN, one of these ABN-TAU pairs. The likelihood of an ABN-TAU pair being selected was governed by an
aw. ABN-TAU pairs with higher
aw were more likely to be selected than those with lower
aw. In the example above, the first ABN-TAU pair would have a 70% chance of being selected (
aw=70), while the second pair would have a 30% chance (
aw=30).
This approach assigned each ABN in the profiled population to a single TAU. As a result, each TAU may have 0, 1 or many ABNs linked to it. In addition, each EG can be represented by one or multiple TAUs, although not every TAU within each EG was necessarily selected (e.g. non-employing TAUs).
Although some ABNs and jobs (and therefore employees) may be allocated to TAUs in which they do not operate, this should have minimal impact on the experimental statistics at the aggregate level (for example the distribution of business-level variables such as Industry).
The ABN to TAU mapping process would benefit from improved coverage and quality of information collected as part of the ABSBR business profiling.
Diagram 3: The Integrated Dataset
 (a) This includes all ABNs ever registered up to and including the 2011-12 financial year and does not reflect those active in the reference period.
(a) This includes all ABNs ever registered up to and including the 2011-12 financial year and does not reflect those active in the reference period.
INTEGRATED DATASET
The Integrated Dataset is comprised of three main subsets (files) representing three separate domains in the linked employer-employee data. These are employee-level data (the Employee File), job-level data (the Job File), and business-level data (the Business File). These files are linked together using unique keys where a link is possible, or left unlinked where no link could be made.
Employee File
The Employee File contains data relating to each employee. This includes demographic and aggregate earnings information, and selected information about jobs held. The Employee File contains all of the data items from the Client Register and Client Dataset extracts (see Data Sources), as well as the following derived data items:
- Earnings
- Items calculated using the Job File
- Industry of main job
- Number of jobs
- Multiple job holder status
- Number of concurrent jobs (for multiple job holders).
Job File
The Job File includes data relating to each job. This includes unique identifiers for employees and businesses, information about each job, whether the jobs is held concurrently with other jobs, and information about the business to which each job links. The Job File contains all of the data items on the Individual PAYG Dataset and the EABLD extract (see
Data Sources), as well as the following derived data items:
- Occupation in main job (from the Employee File)
- Main job
- First job (for multiple job holders)
- Second job (for multiple job holders).
Business File
The Business File includes information relating to each business to which an Individual PAYG Dataset record is linked. The Business File contains all of the data items on the EABLD extract (see
Data Sources).
INTEGRATION RESULTS
At the completion of the linking process:
- the Integrated Dataset contained 10,334,718 employees, 683,331 businesses, and 13,316,438 jobs;
- 9,751,414 employees (94%) from the Employee File were linked to a job on the Job File;
- 13,316,363 jobs (more than 99%) from the Job File were linked to an employee on the Employee File;
- 13,303,850 jobs (more than 99%) from the Job File were linked to a business on the Business File. Of these jobs:
- 6,746,293 jobs (51%) were linked to a business in the non-profiled population;
- 6,557,557 jobs (49%) were linked to a business in the profiled population;
- 675,571 businesses (99%) were in the non-profiled population, and were linked to 5,278,708 employees (51%) on the Employee File; and
- 7,760 businesses (1%) were in the profiled population, and were linked to 5,514,407 employees (53%) on the Employee File.
As some employees had more than one job during the reference period, these employees may link to more than one business on the Business File.
At the completion of the linking process, there were a number of unlinked records which are still included in the Integrated Dataset:
- 583,304 employees (6%) could not be linked to a job;
- 75 jobs (less than 0.001%) could not be linked to an employee; and
- 12,588 jobs (less than 0.1%) could not be linked to a business.
These unlinked records are due to:
- Employees reporting earnings on their ITR without a corresponding Individual PAYG summary (e.g. persons who worked for cash in hand); and
- Potential errors by employers on the Individual PAYG summary impacting the linking keys - Scrambled Tax File Number (STFN) and Australian Business Number (ABN).
Unlinked ABNs were examined and approximately 36% were found to be invalid. These errors are likely the result of erroneous data (e.g. typographical errors or Australian Company Numbers in place of ABNs) entered by employers on an Individual PAYG summary.
INTEGRATED DATASET COMPLETENESS
The following section highlights the completeness of some key data items on the Integrated Dataset.
Table 1: Inadequately defined, not stated or missing information
|
 | Data items | Number of Records |
| | (‘000) | % |
|
| Employee File | Geography – State and territory | 189.3 | 1.8 |
| Geography – Statistical Area Level 4 | 211.7 | 2.1 |
| Occupation of main job | 425.2 | 4.1 |
|
| Job File | One date in PAYG | 126.3 | 0.9 |
| Both dates in PAYG | 98.2 | 0.7 |
|
| Business File | Employment size | 39.3 | 5.8 |
| Business turnover | 17.7 | 2.6 |
| Industry | 8.0 | 1.2 |
| Institutional sector | 8.0 | 1.2 |
|
As seen in Table 1, there is a minimal amount of data that is unable to be defined or is missing following the minimal cleaning applied to the Integrated Dataset.
For further information on the distribution of key data items on the Integrated Dataset, see
Appendix 1.
DATA CLEANING
Employee records with missing or extremely large, erroneous earnings (as reported on their ITR) impact on the detailed analysis of earnings. Limited cleaning was performed on the Integrated Dataset in order to adjust for missing earnings data, and to amend or remove extreme outliers.
Earnings cleaning
Employee records with $0 earnings on an ITR (0.7%) were edited. The gross payments from each job (as recorded on Individual PAYG summaries) were aggregated, and this value replaced the $0 earnings value. As earnings are comprised of amounts other than gross payments, these records likely have slightly understated earnings compared to what would otherwise be reported on an ITR.
Outlier cleaning
Extreme earnings outliers were identified within each employee age and occupation strata. These employee records were further examined by confronting their earnings data against the aggregate of all gross payments for that employee. Records which either had no gross payment data, or for whom the differences were not reconcilable, were identified as extreme outliers and amended in one of two ways. Firstly, if gross payment data existed, the earnings value was deleted and replaced with the aggregate gross payments amount for that employee. Secondly, if gross payment data was not available, the earnings value was excluded from the calculation of the experimental statistics on employee earnings (although the employee record still contributed to statistics on employees). This cleaning affected in total approximately 0.001% of employees.
 Print Page
Print Page
 Print All
Print All