TECHNICAL NOTE DATA QUALITY
INTRODUCTION
1 When interpreting the results of a survey it is important to take into account factors that may affect the reliability of the estimates. Estimates in this publication are subject to both non-sampling and sampling errors.
NON-SAMPLING ERROR
2 Non-sampling errors may arise as a result of errors in the reporting, recording or processing of the data and can occur even if there is a complete enumeration of the population. These errors can be introduced through inadequacies in the questionnaire, treatment of non-response, inaccurate reporting by respondents, errors in the application of survey procedures, incorrect recording of answers and errors in data capture and processing.
3 The extent to which non-sampling error affects the results of the survey is difficult to measure. Every effort is made to reduce non-sampling error by careful design and testing of the questionnaire, training and supervision of interviewers, and extensive quality control procedures at all stages of data processing.
4 The Household Use of Information Technology (HUIT) 2010-11 survey included a question on the type of broadband connection that households have. This question was originally intended to capture all of the connection types used by the household. However, the question appeared to be interpreted by survey respondents as asking for the household's main type of broadband connection (99% of respondents indicated only one type of broadband category). Therefore, the data for this question have been adjusted and presented on the basis that the question asked for the main household broadband connection.
SAMPLING ERROR
5 Since the estimates in this publication are based on information obtained from a sample, they are subject to sampling variability. That is, they may differ from those estimates that would have been produced if all dwellings had been included in the survey. One measure of the likely difference is given by the standard error (SE), which indicates the extent to which an estimate might have varied by chance because only a sample of dwellings (or occupants) was included. There are about two chances in three (67%) that a sample estimate will differ by less than one SE from the number that would have been obtained if all dwellings had been included, and about 19 chances in 20 (95%) that the difference will be less than two SEs.
6 Another measure of the likely difference is the relative standard error (RSE), which is obtained by expressing the SE as a percentage of the estimate:

7 RSEs for HUIT statistics have been calculated using the Jackknife method of variance estimation. This involves the calculation of 30 'replicate' estimates based on 30 different subsamples of the obtained sample. The variability of estimates obtained from these subsamples is used to estimate the sample variability surrounding the estimates.
8 In this publication, sampling variability is indicated through use of annotations which have been produced using RSEs. Limited space does not allow the SEs and/or RSEs of all estimates to be shown in this publication. Only RSEs for Table 1 of Datacube 3 are included in this section. RSEs for all data included in this release are available upon request.
9 In this publication, only estimates (numbers and proportions) with RSEs less than 25% are considered sufficiently reliable for most purposes. Estimates with RSEs between 25% and 50% have been included and are preceded by an asterisk (e.g. *3) to indicate they are subject to high sample variability and should be used with caution. Estimates with RSEs greater than 50% are preceded by a double asterisk (e.g. **2) to indicate that they are considered too unreliable for general use.
CALCULATION OF STANDARD ERRORS
10 SEs can be calculated using the estimates (counts or means) and the corresponding RSEs:
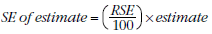
11 For example, Table 1 of Datacube 3 shows that the estimated number of households with internet access in 2010–11 is 6,724,000. In the corresponding RSE table (see the RSE table at the end of the Technical Note), the RSE for this estimate is shown to be 0.4%. Applying the above formula, the SE is:
SE = 0.004 x 6,724,000 = 27,000 (rounded to the nearest 1,000)
12 Therefore there are about two chances in three that the value that would have been produced if all dwellings had been included in the survey will fall within the range 6,697,000 to 6,751,000 and about 19 chances in 20 that the value will fall within the range 6,670,000 to 6,778,000.
PROPORTIONS AND PERCENTAGES
13 Proportions and percentages formed from the ratio of two estimates are also subject to sampling errors. The size of the error depends on the accuracy of both the numerator and the denominator. A formula to approximate the RSE of a proportion is given below. This formula is only valid when x is a subset of y.
![Equation: RSE (x / y) = square root of ([RSE (x)] squared - [RSE (y)] squared)](/ausstats/abs@.nsf/0/b01a290dd4c0a521ca257c89000e4261/Body/0.2A50!OpenElement&FieldElemFormat=gif)
14 For example, in Table 1 of Datacube 3 the estimate for the proportion of households in Western Australia with broadband access in terms of those with internet access is 92%.
15 The RSE of the estimated number of households in Western Australia with broadband access is 1.6%, and the RSE of the estimated number of households in Western Australia with internet access is 1.1%.
16 Applying the above formula, the RSE of the proportion is:
![RSE of a proportion example: RSE of (x/y)= square root of [(1.6) squared - (1.1) squared)]](/ausstats/abs@.nsf/0/b01a290dd4c0a521ca257c89000e4261/Body/0.795A!OpenElement&FieldElemFormat=gif)
17 This then gives an SE for the proportion (%) of 0.012 x 92 = 1 percentage point.
18 Therefore there are about two chances in three that the proportion of households in Western Australia with broadband access is between 91% and 93%, and 19 chances in 20 that the proportion is within the ranges 90% to 94%.
DIFFERENCES
19 Published estimates may also be used to calculate the difference between two survey estimates (of numbers or percentages). Such an estimate is subject to sampling error. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
![Equation: SE (x - y) = square root of ([SE (x)] squared - [SE (y)] squared)](/ausstats/abs@.nsf/0/b01a290dd4c0a521ca257c89000e4261/Body/0.92D0!OpenElement&FieldElemFormat=gif)
20 While this formula will only be exact for differences between separate and uncorrelated characteristics or subpopulations, it provides a good approximation for all differences likely to be of interest in this publication.
SIGNIFICANCE TESTING
21 A statistical significance test for any comparisons between estimates can be performed to determine whether it is likely that there is a difference between the corresponding population characteristics. The standard error of the difference between two corresponding estimates (x and y) can be calculated using the formula in paragraph 19. This standard error is then used to calculate the following test statistic:
![Equation: Test statistic = ([x - y] / [SE(x - y)])](/ausstats/abs@.nsf/0/b01a290dd4c0a521ca257c89000e4261/Body/0.9E98!OpenElement&FieldElemFormat=gif)
22 If the value of this test statistic is greater than 1.96 then there is evidence, with a 95% level of confidence, of a statistically significant difference in the two populations with respect to that characteristic. Otherwise, it cannot be stated with confidence that there is a real difference between the populations with respect to that characteristic.
RELATIVE STANDARD ERRORS – Type of internet access at home, by selected characteristics,
2010 -11
 | | Households with internet access | Broadband | Dial-up | Don't know |
| | % | % | % | % |
|
| Households | | | | |
| With children under 15 | 0.7 | 0.5 | 9.9 | 14.7 |
| Without children under 15 | 0.6 | 0.3 | 3.7 | 7.3 |
| | | | | |
| State or Territory | | | | |
| New South Wales | 0.8 | 0.4 | 6.9 | 11.5 |
| Victoria | 0.8 | 0.6 | 8.7 | 12.2 |
| Queensland | 0.8 | 0.4 | 5.6 | 11.0 |
| South Australia | 1.1 | 0.7 | 12.0 | 15.7 |
| Western Australia | 1.1 | 0.9 | 10.7 | 16.5 |
| Tasmania | 1.8 | 0.9 | 10.9 | 21.7 |
| Northern Territory | 2.7 | 0.8 | 13.2 | 23.0 |
| Australian Capital Territory | 1.7 | 0.7 | 13.1 | 19.2 |
| | | | | |
| Area of usual residence | | | | |
| Capital city | 0.5 | 0.3 | 5.1 | 8.2 |
| Balance of State/Territory | 0.7 | 0.3 | 4.0 | 7.3 |
| | | | | |
| Equivalised household income | | | | |
| Less than $40,000 | 1.4 | 0.4 | 5.9 | 8.4 |
| $40,000 to $79,999 | 1.7 | 0.4 | 8.0 | 14.7 |
| $80,000 to $119,000 | 3.0 | 0.7 | np | np |
| $120,000 or over | 5.0 | 1.0 | np | np |
| Could not be determined | 1.8 | 0.7 | 8.0 | 9.3 |
| | | | | |
| Household income | | | | |
| Less than $40,000 | 1.6 | 0.6 | 6.6 | 11.1 |
| $40,000 to $79,999 | 1.8 | 0.5 | 7.9 | 13.8 |
| $80,000 to $119,000 | 2.2 | 0.4 | 10.4 | 18.5 |
| $120,000 or over | 2.4 | 0.5 | 13.2 | 24.5 |
| Could not be determined | 1.8 | 0.7 | 8.0 | 9.3 |
| | | | | |
| Equivalised household income quintiles | | | | |
| Lowest quintile | 2.3 | 1.0 | 11.2 | 14.5 |
| Second quintile | 2.5 | 0.8 | 8.8 | 14.6 |
| Third quintile | 2.4 | 0.6 | 9.4 | 17.5 |
| Fourth quintile | 2.3 | 0.6 | 10.7 | 18.9 |
| Highest quintile | 2.2 | 0.5 | 11.2 | 18.5 |
| Could not be determined | 1.8 | 0.7 | 8.0 | 9.3 |
| | | | | |
| Remoteness area | | | | |
| Major cities of Australia | 0.9 | 0.3 | 5.3 | 8.2 |
| Inner regional Australia | 2.4 | 0.5 | 5.4 | 11.2 |
| Outer regional Australia | 6.5 | 0.7 | 8.0 | 15.7 |
| Remote Australia | 17.4 | 1.7 | 17.1 | 32.4 |
| | | | | |
| Urban or rural area of residence | | | | |
| Urban | 0.9 | 0.3 | 4.0 | 6.4 |
| Rural | 6.6 | 0.8 | 9.9 | 17.3 |
| | | | | |
| Total | | 0.4 | 0.2 | 3.7 | 6.2 |
 Quality Declaration
Quality Declaration  Print Page
Print Page
 Print All
Print All