INTRODUCTION
1 The Characteristics of Small Business Operators Survey, Australia, was conducted in June 2004 as a supplementary topic to the Labour Force Survey.
2 The Labour Force Survey is a household based survey, designed to regularly collect specific data on demographic and labour force characteristics of the Australian population. From time to time supplementary and special surveys of particular aspects of the labour force or other subjects are carried out.
DATA COLLECTION METHOD
3 The data were collected by trained interviewers over a two week period. When completing the Labour Force Survey, those people whose main job or second job was operating a small business with less than 20 employees were asked some additional questions relating to the operations of that business.
4 The supplementary survey asked small business operators to provide details on themselves as operators of small businesses and on the operations of their particular business. If there was more than one operator of the same small business in a household only one of the operators was asked to complete the questions relating to the operations of that business.
5 The above method enabled the estimation of two discrete populations:
(i) Small business operators and their characteristics.
(ii) Small businesses and their characteristics.
SCOPE OF THE SURVEY
Business size
6 Only those businesses which employ less than 20 people and their operators are included in the survey results.
Industry
7 All businesses identified were classified according to the Australian and New Zealand Standard Industrial Classification (ANZSIC) (cat. no. 1292.0), a detailed description of which appears in ANZSIC 1993.
The survey included businesses in the following industries:
Mining
Manufacturing
Construction
Wholesale trade
Retail trade
Accommodation, cafes and restaurants
Transport and storage
Communication services
Finance and insurance
Property and business services
Education, Health and community services
Cultural and recreational services
Personal and other services.
Geographical areas
8 The survey covered both rural and urban areas in all states and territories, excluding some 175,000 persons living in remote and sparsely settled parts of Australia. The exclusion of these persons will have only a minor impact on any aggregate estimates that are produced for individual states or territories, with the exception of the Northern Territory where such persons account for over 20% of the population.
Persons
9 The population for the survey includes all persons aged 15 years or over except:
- diplomatic personnel of overseas governments
- overseas residents temporarily in Australia
- members of non-Australian defence forces and their dependants stationed in Australia
- members of the permanent Australian defence forces
- boarding school students
- people in institutions such as hospitals, sanatoria and inmates of jails, reformatories etc.
10 While these categories of people have an effect on the measurement of labour force levels, their exclusion is not expected to have significant impact on the identification of small businesses.
SURVEY DESIGN
11 As the Characteristics of Small Business Operators Survey is a supplementary survey to the Labour Force Survey, it has the same basic design. The survey was based on a multi-stage area sample of private dwellings (about 30,000 houses and flats), and covered about one-half of one per cent of the population of Australia.
COVERAGE OF THE SURVEY
12 Coverage rules are applied which aim to ensure that each person is associated with only one dwelling, and hence has only one chance of selection. The chance of a person being enumerated at two separate dwellings in the one survey is considered to be negligible.
13 Persons who are away from their usual residence for six weeks or less at the time of the interview are enumerated at their usual residence.
PREVIOUS ESTIMATES
14 Where comparative data are available, this publication presents estimates from the June 2003 Characteristics of Small Business Operators Survey.
RELIABILITY OF ESTIMATES
15 The estimates provided in this publication are subject to two types of error: sampling error and non-sampling error.
Sampling error
16 As the estimates in this publication are based on information obtained from occupants of a sample of dwellings they are subject to sampling variability. That is, the estimates may differ from those that would have been produced if all dwellings had been included in the survey.
17 One measure of the likely difference is given by the standard errors (SEs) (see the tables in the Appendix), which indicate the extent to which an estimate might have varied by chance because only a sample of dwellings was included. There are about two chances in three (67%) that a sample estimate will vary by less than one SE from the estimate that would have been obtained if all dwellings had been included, and about nineteen chances in twenty (95%) that the difference will be less than two SEs.
18 Another measure of the sampling variability is the relative standard error (RSE), which is obtained by expressing the SE as a percentage of the estimate to which it refers. The RSE is a useful measure in that it provides an immediate indication of the error likely to have occurred due to sampling expressed as a percentage of the estimate.
19 As the Appendix shows, the size of the SE increases with the size of the estimate. However, the smaller the estimate the higher the RSE. Thus, larger estimates will be relatively more reliable than smaller estimates.
20 Very small estimates are subject to large RSEs, so for most practical purposes are unreliable. In the tables in this publication, only estimates with RSEs of less than 25% are considered reliable for most purposes. Estimates with RSEs greater than 25% but less than or equal to 50% are preceded by an asterisk (e.g. *3.4) to indicate they are subject to high SEs and should be used with caution. Estimates with RSEs of greater than 50%, preceded by a double asterisk (e.g. **0.3), are considered too unreliable for general use and should only be used to aggregate with other estimates to provide derived estimates with RSEs of 25% or less.
21 Space does not allow for separate indication of the standard errors of all estimates in this publication. As a guide, the Appendix provides an average standard error applicable for estimates of the number of small business operators and the number of small businesses for any classification. Each SE Appendix is derived from a mathematical model, referred to as the 'SE model', which is created using data from the survey. It should be noted that the SE model only gives an approximate value for the SE for any particular estimate, since there is some minor variation between SEs for different estimates of the same size.
22 If the actual value for a particular estimate is not shown in the Appendix, an approximate SE can be derived by taking the SEs shown for estimates on either side of the required value and interpolating a figure within that range.
Calculations of Standard Error (SE)
23 An example of the calculation and the use of SEs in relation to estimates of the number of small business operators is as follows. Table 2.1 shows that the estimated number of male small business operators in New South Wales is 411,100. Since this estimate is between 300,000 and 500,000, Appendix A shows that the SE for New South Wales will be between 10,400 and 12,900, and can be approximated by interpolation using the following general formula:
SE of estimate = lower SE + (((size of estimate - lower estimate) / (upper estimate - lower estimate))x(upper SE - lower SE))
= 10,400 + (((411,100 - 300,000) / (500,000 - 300,000)) x (12,900 - 10,400))
= 11,789
= 11,800 (rounded to the nearest 100)
24 Therefore, there are about two chances in three that the value that would have been produced if all dwellings had been included in the survey will fall in the range 399,300 to 422,900 and about 19 chances in 20 that the value will fall in the range 387,500 to 434,700.
25 Similarly, SEs are calculated for estimates of the number of small businesses using the Appendix. For example, table 3.1 shows that the estimated total number of small businesses in Australia is 1,269,900. This estimate is between 1,000,000 and 2,000,000, so the SE for this estimate will be between 18,100 and 26,200, and can be approximated using the same interpolation formula as above, with the resulting SE being 20,300 (rounded to the nearest 100).
Proportions and percentages
26 Proportions and percentages formed from the ratio of two estimates are also subject to sampling errors. The size of the error depends on the accuracy of both the numerator and the denominator. A formula to approximate the RSE of a proportion is given below. This formula is only valid when x is a subset of y.
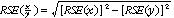
27 For example, in table 2.1, the estimate for the total number of small business operators in NSW is 579,100. The estimated number of male small business operators in NSW is 411,100, so the proportion of small business operators in NSW who are male is 411,100/579,100 or 71.0%. The SE of the total number of small business operators in NSW may be calculated by interpolation as 13,600. To convert this to a RSE we express the SE as a percentage of the estimate, or 13,600/579,100 = 2.3%. The SE for the number of male small business operators in NSW was calculated above as 11,800, which converted to a RSE is 11,800/411,100 = 2.9%. Applying the above formula, the RSE of the proportion is:
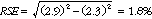
giving a SE for the proportion (71.0%) of 1.3 percentage points (=(71.0/100)*1.8).
28 Therefore, there are about two chances in three that the proportion of small business operators in NSW who are male is between 69.7% and 72.3% and 19 chances in 20 that the proportion is within the range 68.4% to 73.6%.
29 Similarly, SEs can be calculated for estimates of the proportion of small businesses using the same formula.
Differences
30 Published estimates may also be used to calculate the difference between two survey estimates (of numbers or percentages). Such an estimate is subject to sampling error. The sampling error of the difference between two estimates depends on their SEs and the relationship (correlation) between them. An approximate SE of the difference between two estimates (x-y) may be calculated by the following formula:
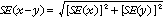
31 While this formula will only be exact for differences between separate and uncorrelated characteristics or sub-populations, it is expected to provide a good approximation for all differences likely to be of interest in this publication.
Non-sampling errors
32 The imprecision due to sampling variability, which is measured by the SE, should not be confused with inaccuracies that may occur due to non-sampling errors.
33 Non-sampling errors can occur whether the estimates are derived from a sample or from a complete enumeration. Three major sources of non-sampling error are:
- Inability to obtain comprehensive data from all people included in the sample. These errors arise because of differences which exist between the characteristics of respondents and non-respondents.
- Errors in reporting on the part of both respondents and interviewers. These reporting errors may arise through inappropriate wording of questions, misunderstanding of what data are required, inability or unwillingness to provide accurate information and mistakes in answers to questions.
- Errors arising during processing of the survey data. These processing errors may arise through mistakes in coding and data recording.
34 Non-sampling errors are difficult to measure in any collection. However, every effort was made to minimise these errors. In particular, the effect of the reporting and processing errors described above was minimised by careful questionnaire design, intensive training and supervision of interviewers, asking respondents to refer to records whenever possible and extensive editing and quality control checking at all stages of data processing.
SURVEY ESTIMATION AND WEIGHTING PROCEDURES
35 Estimates derived from the survey are obtained by using a calibrated weighting procedure which ensures that the survey estimates conform to an independently estimated distribution of the population by area of residence, age and sex.
36 Two separate weights were used for the survey:
- a person weight used in the estimation of small business operators
- a business weight used in the estimation of small businesses.
37 Each person in the sample is assigned a ‘weight’ which takes into account their probability of selection in the sample from their region, with adjustments to account for under-enumeration (e.g. non-response) at the age and sex level.
38 The ‘weights’ are also adjusted to reduce the bias introduced by varying levels of non-response in different sub-groups of the population.
39 Business weights are derived from the person weights using partner per business information.
 Print Page
Print Page
 Print All
Print All