|
|
MEASURES OF LOCATION
If observations of a variable are ordered by value, the median value corresponds to the middle observation in that ordered list. The median value corresponds to a cumulative percentage of 50 per cent. The position of the median is the:
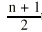 th value, where n is the number of values in a set of data.
There are as many values above the median as there are below. After the data have been placed in ascending order:
MEDIAN = THE MIDDLE VALUE OF A SET OF DATA
The median is usually calculated for numeric variables, but may also be calculated for an ordinal nominal variable.
DISCRETE VARIABLES
EXAMPLE th value, where n is the number of values in a set of data.
There are as many values above the median as there are below. After the data have been placed in ascending order:
MEDIAN = THE MIDDLE VALUE OF A SET OF DATA
The median is usually calculated for numeric variables, but may also be calculated for an ordinal nominal variable.
DISCRETE VARIABLES
EXAMPLE
| 1. | Cathy Freeman is one of Australia’s leading Aboriginal athletes. In a typical 200 metre training session she runs the following times:
26.1, 25.6, 25.7, 25.2 and 25.0 seconds. Find the median time. |
 | First the values are put in ascending order: 25.0, 25.2, 25.6, 25.7, 26. |
| Median |
| = (n + 1 )/2th value |
| = (5+1)/2th = 3rd value |
| = 25.6 seconds (2 values above and 2 below) |
| |
| 2. | If Cathy then runs her 6th 200 metre run in 24.7 seconds, what is the median value now? |
| Again the data are put in ascending order: |
| 24.7, 25.0, 25.2, 25.6, 25.7, 26.1 |
| Median = (6+1)/2th=3.5th value |
| |
| Therefore, it lies between the 3rd and 4th values. Since there is an even number of observations, there is no distinct middle value. The median is calculated by averaging the two middle values 25.2 and 25.6. |
| Thus: |
| (25.2 +25.6) ÷ 2 |
| = 25.4 seconds |
| |
| 3. | Ordered stem and leaf tables make it simple to calculate the median, particularly if cumulative frequencies have been calculated. Consider the heights of the 50 Year 10 girls.
Using a stem and leaf table: |
|
|
| Cumulative frequency |
|
|
|
| 4 |
|
|
| 11 |
|
|
0 1 1 1 1 2 2 2 2 2 2 3 3 3 4 4 4 4
| 29 |
|
|
0 1 1 1 1 2 2 2 2 2 2 3 3 3 4 4 4 4
| 40 |
|
|
| 46 |
|
|
| 50 |
|
|
| |
There are 50 pieces of data, so the median is the value of the:
(50+ 1)/2th = 25.5th observation
Therefore, the median lies between the values of the 25th and 26th observations.
That is, the median lies between 163cm (25th observation) and 164cm (26th observation). The median is found by averaging these 2 values.
| Thus: | (163 + 164) ÷ 2 |
| | | = 163.5 cm
(Since height is a continuous variable, 163.5cm is an acceptable median value.) |
FREQUENCY TABLE (DISCRETE VARIABLES)
| 4. | If the scores from 10 netball matches are placed in a frequency table, what is the median? |
| No. of goals (x) | Frequency (f)) | | |
|
| | |
| 4 | 1 |
| |
| 5 | 2 | | |
| 6 | 0 | | |
| 7 | 2 | | |
| 8 | 4 | | |
| 9 | 1 | | |
The median is the (10 + 1)/2th = 5.5th value.
From the frequency column in the above table, it will be either the 5th value (7) or the 6th value (8).
If the average of these is calculated, the result is 7.5.
NOTE:
Technically, the median should be a possible variable value. In the above example, the variable is discrete and always a whole number. Therefore, 7.5 is not a possible variable value and is strictly not the median. Some argue that 8 is a more appropriate median. For our purposes 7.5 is acceptable.
GROUPED VARIABLES (CONTINUOUS OR DISCRETE)
| 5. | Grouping the data in Example 3 will allow you to find the median using a cumulative frequency graph. The end-points of height intervals, cumulative frequency and cumulative percentage columns are shown in the following table. |
Height (centimetres) | Frequency (f) | End-point (x) | Cumulative frequency | Cumulative percentage | |
| |
|
|
| 150 | 0 | 0 | |
150-<155 | 4 | 155 | 4 | 8 | |
155-<160 | 7 | 160 | 11 | 22 | |
160-<165 | 18 | 165 | 29 | 58 | |
165-<170 | 11 | 170 | 40 | 80 | |
170-<175 | 6 | 175 | 46 | 92 | |
175-<180 | 4 | 180 | 50 | 100 | |
The cumulative frequency graph can now be plotted.
The median obtained from the cumulative frequency graph is a different value to the median obtained from the stem and leaf table. This is because, unless the graph is drawn precisely with all the information used, you can only find an approximation for the median. (Plotting a detailed graph can be time consuming.)
COMPARING THE MEAN AND MEDIAN
It is possible to have the mean and median of a distribution equal to the same value. This is always the case if distribution is symmetric, and the two values will be close together if distribution is roughly symmetric.
In the example of heights of 50 Year 10 girls, the mean (164cm) is very close to the value of the median (163.5cm). This is because the distribution is roughly symmetric (see the previous stem and leaf table).
However, one number can alter the mean without affecting the median.
Consider the following sets of data that represent the number of goals scored by 3 players in 11 netball matches.
| 1. |
| 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 3 |
| |
| Mean = 22/11 = 2 |
|
| Median: 2 |
| |
| |
|
| 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 4 |
| | Mean = 23/11 = 2.1 |
| | Median = 2 |
| |
| |
|
| 1, 1, 1, 2, 2, 2, 2, 2, 3, 3, 14 |
| |
| Mean = 33/11 = 3 |
|
| Median = 2 |
The 3 sets of data are identical except for the last observation values (3, 4 and 14).
The median does not alter, because it is only dependent on the middle observation’s value. Whereas, the mean does change, because it is dependent on the average value of all observations. So, in the above example, as the last observation’s value increases, so does the mean.
In the 3rd set, the value of 14 is very different from any other values. When an observation is very different from all other observations in a data set it is called an outlier (see section Stem and Leaf Plots).
In some cases, outliers can occur due to error or deliberate misinformation and, as a result, the measure of central tendency that is used should not include them. In other cases, outliers can be significant pieces of data, so the measure of central tendency used should include them.
| 2. | When house prices are referred to in newspapers, the median price is quoted. Why is this measure used and not the mean?
There are many moderately priced houses, but also some expensive ones and a few very expensive ones. If the mean figure was given, it could be quite high as it responds to prices of more expensive houses. The median gives a more accurate and realistic value of the prices faced by most people. |
| |
| 3. | The ABS uses the median to calculate the centre of a population’s age distribution. For the Melbourne Statistical Division (MSD) the median age of a person at the time of the 1996 Census was 33 years. Why is this measure used and not the mean?
The mean would include all extreme age values, and thus be influenced by them. In this case, the median gives a better indication of centre. (The mean age was 35 years.) |
| |
| 4. | In cricket, a batter’s average is calculated by adding the number of runs scored and dividing by the number of times they have been dismissed. Consider two batters, X and Y. Both are dismissed five times. |
X scores: 0, 0, 0, 0, and 200
Y scores: 34, 36, 39, 42, and 44
Batter X’s average is 40 while that of Y is 39. However, X’s average has been influenced by a large score of 200: in this case an outlier. A better indication of batting performance may be the median.
For X the median is 0, while for Y it is 39. It seems clear from this that Y is a better batter. But what about X’s great score of 200? Perhaps a better description of X’s batting performance would be to say that, ‘X scored 200 runs in one innings, but in the other four innings X’s average was 0'.
|
|
 Print Page
Print Page
 Print All
Print All